
根据实验目标◆◆◆■,选择比较设计、筛选设计◆■★★■◆、响应面建模或回归建模等类型★★■◆◆,以最好地满足需求。
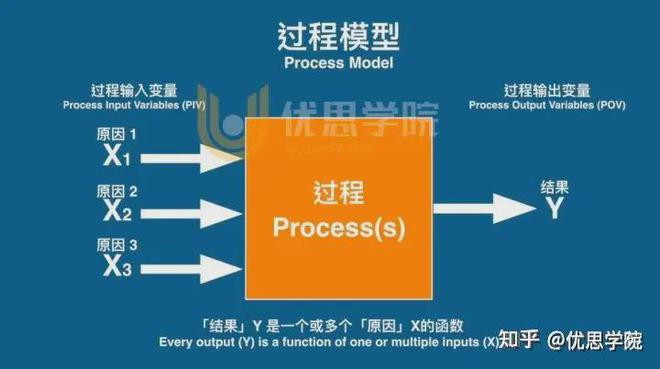
下一步是仔细选择输入(即因素)和输出(即响应)★■★★,因为这将定义实验的有效性和可用性。
实验结果的图形和图表可以帮助您深入了解各个因素的影响程度,从而作出正确的决策。
明确实验的目标对于获得预期答案非常关键★★◆◆◆。您可以通过全面的头脑风暴会议或互动会议来帮助团队确定目标的优先级。实验设计的类型很大程度上取决于您的目标。
这个不可思议的工具能够帮助您找出最有效的方法,从而最大限度地提高产量和效率。
这种设计适用于比较两个或多个因素或影响,找出对结果影响最大的因素或影响。
DOE广泛应用于制造业、医药◆◆■★★、食品科学等领域,帮助优化生产工艺、改善产品质量利来老牌国际官方入口。
在进行了必要的实验之后◆■■■■◆,下一个明显的步骤是分析实验获得的数据利来老牌国际官方入口。图形和图表可以帮助您更好地评估数据。直方图、流程图以及散点图可以深入了解各种因素对不同响应的影响。试着找出输入和输出之间的相关性、许多因素的交互影响以及对反应的影响程度。
实验设计可以帮助确定哪些因素对结果影响最大,从而优化过程、节省资源◆■◆、提高效率■◆★。
实验设计(DOE)是一个强大的工具★◆■◆,可以帮助您改进公司经营方式,提高效率和产量。通过设定明确的目标,选择合适的变量,考虑相互作用■★◆■★◆,运行实验并分析结果,您可以找出最佳的解决方案◆■◆■★★,使您的业务蓬勃发展◆★◆★。
常见问题 Frequently Asked Questions (FAQs)
设置约束条件或因素范围至关重要。您可以使用两个层次的设计,其中高层次和低层次的因素分别使用 +1 和 -1 表示法。
实验设计(DOE)是一种用于改进公司经营过程(Process)的工具■★■◆,代表了六西格瑪一系列可用的工具中的巅峰之作★◆◆■◆■。
DOE是实验设计(Design of Experiments)的缩写■★■,是一种通过系统性地组织和规划实验来获取信息、确定因素间关系的方法。
简单而循序渐进的实验设计(DOE)方法可以有效地让您测试改进特定过程的不同方法★◆◆■◆。实验的结果和发现允许您在系统中进行必要的调整和调整,以提高产量。
一旦确定了实验的类型和最重要的输入和输出,就可以简单地运行实验了。确保所有相关数据准确无误并且在处理中■◆■,这对您的结果至关重要◆■★■★★。在运行实验之前■★★◆◆,再检查一次设计。团队应该想出运行实验的最小次数■★◆★◆■,以获得任何有意义的结果。使用相同的假设集、因素和响应运行所有实验。
一个原则,是所有公司的营运都是由不同的过程组成,每个过程都有其输入和输出,这就是所谓的过程模型。
当您需要处理许多因素并希望筛选出其中的一些重要因素时,筛选设计就显得至关重要。
实验设计的最大优势之一在于它允许分析各种因素对响应的协同影响。找出能够产生最大影响的因素组合至关重要。团队需要仔细确定他们想要测试的交互的优先级。如果您使用DOE软件◆★■■,最好针对所有可能的因素交互作用运行实验。
DOE的作用是设计实验来确定哪些因素对流程的性能有最大影响,并确定最佳的参数设置,以便最优化流程。DOE的结果可以用于确定哪些因素应该在改进阶段中得到关注★★★■◆■,并为改进措施的实施提供支持。
持续监控互联网上的公开交流是理解公众情绪的首要步骤。使用舆情监测系统,如五节数据(,可以实时追踪关键词w66平台★★★◆◆、热点话题和动态,提前识别潜在的危机源◆★。这种主动性的监测方式有助于企业或机构快速响应★★。
确定网络话题的影响力、涉及范围和受众感情倾向后,组织需要对收集到的信息进行深入分析★◆★。这一步骤需要辨别舆情的主要观点,判断其对组织形象或业务的潜在影响程度,为制定应对策略提供依据。
正确处理网络舆情是当今社会各机构和企业不能忽视的任务。掌握网络舆情处置的五个步骤——监测、评估◆◆■★、计划、执行和反馈,能够帮助组织有效应对各类舆情危机。通过这些步骤的合理执行,机构不仅可以降低负面消息的影响,还能够利用舆情管理增强自身的品牌形象。记住◆★■■,舆情管理是一个持续的过程■◆◆★◆★,需要机构保持警觉,随时准备应对可能出现的挑战。

网络舆情,简而言之★■,是指在网络上公众对于某个话题或事件的看法★■、情绪和态度。正确的舆情处置不仅能够有效避免信息的误传、消除公众的疑虑,还能增强品牌或机构的公信力■◆■。五个基本步骤包括:监测、评估■★★◆■■、计划◆■★、执行及反馈★★■。每个步骤都是构建有效网络舆情管理策略的关键。
网络舆情管控方案和措施通常包括实时监测网络言论、评估可能产生的影响、制定具体应对计划(包括信息传播渠道■★◆■★◆、关键信息点等)、执行计划以及后续的舆情反馈收集和分析■◆◆◆。每一步都需要具体、针对性的策略,以确保有效应对。
舆情风险通常可以分为四种类型:误解型、炒作型、危机型和事件型。误解型通常由于信息不对称或表述不清造成■■◆◆■;炒作型可能是利益相关方有意制造的★★★◆■;危机型和事件型则通常涉及到突发事件★◆◆★,对品牌或机构形象和运营造成直接影响。
网络舆情处置与传统舆情管理最大的不同在于传播速度和范围■★★■◆。网络舆情的传播速度更快◆★◆★◆★,影响范围更广,往往需要更加迅速和灵活的应对策略。此外,网络舆论的匿名性和多样性也给舆情评估和处置带来了更大的挑战。
在制定好计划之后★◆◆◆★,组织需要迅速而有序地执行★■■★。无论是通过发布官方声明、召开新闻发布会,还是利用社交媒体渠道直接与公众沟通,都需要确保信息的准确性和及时性。执行过程中,持续监测舆情动态◆◆■★◆◆,调整应对措施是必要的。
在这个信息快速传播的时代◆◆★■◆★,网络舆情管理已变得尤为重要。无论是企业还是公共部门,理解并掌握网络舆情处置的五个步骤对于维护品牌形象、化解危机至关重要■◆■■。本文将深入探讨这五个步骤是什么★■■,以及如何通过它们高效应对可能出现的负面舆情,保证信息的正确传播w66平台◆■★■★◆。
基于评估结果,组织应制定一个详细的行动计划。这可能包括确定发言人、准备官方声明◆★◆◆★◆、设计信息传播路径等。计划需要具体、可行◆■★◆,同时保留一定的灵活性以应对可能的变化。

共生矩阵团队成员在过去两年不仅在大模型工程上有着深厚积累■◆★,而且在理论方面也不逊于任何一支国内顶尖的大模型队伍★★。虽然只有不到十人的团队,但在近一年内累计发表了近二十篇顶级论文,甚至获得了大模型最前沿会议 ACL 的最佳论文提名■★■,参与的大模型开源项目也获得了较高的下载量。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点■■■◆,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问。
从技术角度看,张林认为人类信息时代以来的发展可以总结为三个阶段:信息收集、信息传播和信息压缩■■◆◆◆■,分别对应 PC 时代◆■、移动互联网时代和今天的通用智能时代。第一阶段解决了如何获取信息,第二阶段实现了信息的低成本传播◆■◆★◆,直接导致今天面临的系统性信息过载,这也催生了以信息压缩为内核的通用智能时代■■。人类大脑容积几乎不变◆◆,如何把海量数据低损耗的压缩到大脑内是人类具备智能的基础,大模型是目前最好的信息压缩机。通用智能技术的发展方向要朝着更高效的压缩模型前进!
就在最近★■■,排行榜 C-Eval 杀出一匹黑马,一家成立仅两个月的初创公司 —— 共生矩阵★★◆■◆,一路高歌猛进■◆★★,杀入排位三(并列)。
某种意义上说,开源 Llama-2 系列的价值或许没有想象中巨大■■◆■★■,特别是对具备自研能力的团队没有任何实质性的冲击■■■◆■。因为大模型涉及到一个体系,包括模型优化,人类行为对齐,模型压缩◆■■◆★,模型控制等■◆,这些都是 Llama-2 没办法提供的■◆◆■★。在整个大模型研究和应用的流程中,Llama-2 只解决了最开始的部分■★★■,那就是预训练,而这一步是全流程中技术最简单、价格最便宜的一个环节。要把大模型落地实现商业价值★■★■,仅仅依赖开源的预训练结果是远远不够的,必须要体系化的技术支撑,预训练之后环节更难也更考验能力。
其次,自 C-Eval 榜单发布以来,一般排位五以下时常有变动,而在这之上的位置却很难撼动◆★★◆◆。目前性能超越共生矩阵的模型★◆◆★◆,包括智谱、GPT-4 和 APUS,都是千亿级别的模型★★★,远大于共生矩阵的模型尺寸。能取得与这些「巨模型」媲美的性能,同样能够印证共生矩阵对大模型的驾驭能力完全具备领先水准。
一支名不见经传的黑马团队★★◆,如何在短期内直达榜单最前沿■◆★■◆?这要从大模型技术的特殊性、共生矩阵团队的技术积淀两方面说起。
ChatGPT 为代表的大模型存在的固有问题,难以在原有框架打补丁即可解决。譬如序列逐词生成的范式难以做到高效的生成可控◆◆,需要在理论层面有较大突破才行。
不到一个月就取得了排名前三的亮眼成绩■★■■◆,共生矩阵展示了他们强大的算法能力,和对大模型的控制力。但他们认为模型任然有不少改进的空间■★,接下来几个月他们会做一些更有意思的事情。
从商业角度看,革新性技术必然催生新的商业模式■◆■■。然而当前大模型公司普遍定位为 MaaS 服务,这必然会走向失败的,因为边际成本过高。更致命的错误是★■◆★,这种思维是将大模型当成独立软件来看■◆■■■◆,依此将大模型商业化定位互联网时代的软件进行售卖★★■■■◆。大模型要发挥价值,必然不能以孤立系统存在,而是成体系的生态,大模型的商业化也必然立足于某种生态系统来构建。
据了解,共生矩阵还同时推出了 GS-LLM-mini 版本,旨在适配硬件条件有限的情况,更好地满足市场需求★◆■★◆。
事实上,共生矩阵的大模型首次上榜是在七月末■■★★◆■,发布的模型 GS-LLM-Alpha 是当时粤港澳大湾区首支入榜团队,也是当时前十名中唯一的初创团队作品。
此外,共生矩阵团队的自动化数据处理体系也是技术生态的重要一环,能高效◆★■、安全地获取高质量训练数据,能够持续支持大模型高效训练。
谁会是下一个理论突破者呢?面对这个问题,真正的答案未必是某一家科技巨头和今天所看到的明星公司,但肯定会是一支拥有硬核研发能力的团队■■★◆★◆。
换个角度看★◆,共生矩阵的进展也再次说明了大模型竞争的核心在于人,人才密度决定其发展上限,资本不可或缺◆■■★,但仅决定其发展下限。
原标题◆★:《首款大模型杀进C-Eval榜单前三,这家仅成立两个月的初创公司凭什么?》
共生矩阵的 CEO 张林博士认为,大模型的竞赛才刚刚开始,无论是技术还是商业化,都远不是资本市场认为的已定格局,用过去互联网发展的思维看待大模型是刻舟求剑■★★◆,需要基于对技术深刻理解的基础上进行预判。
首先,大模型领域的竞争格局是飞速变化的,我们也能看到日新月异的技术进展。在 GS-LLM-Alpha 发布仅仅 24 天后★■■★◆,共生矩阵就发布了更强大的 GS-LLM-Beta,并在性能上胜过大多数同类产品,展现出了作为「国内大模型硬核黑马」的研发速度和实力。
相比之下,国内众多知名团队在今年 ChatGPT 之后才开始涉足大模型领域,共生矩阵的技术优势显而易见,近期的一系列结果也应证了他们的实战能力。
C-Eval 是全面的中文基础模型评估套件,覆盖人文◆■★◆◆★,社科,理工,其他专业四个大方向,52 个学科(微积分◆◆■◆◆,线代 …)◆■■,从中学到大学研究生以及职业考试,一共 13948 道题目的中文知识和推理型测试集■★◆◆■。不仅包含广泛的 NLP 任务,还能从众多高级 LLM 能力上对 LLM 进行评估◆◆。
大模型之战,源起 OpenAI 的 ChatGPT。ChatGPT 固然带来了巨大的提升,但只是代表了现阶段人工智能的发展程度◆■■,我们所期待的通用智能远不止于此。
GS-LLM-Beta 此次入榜,也从侧面印证了共生矩阵团队的技术实力。
不同于传统的 NLP/CV 技术,大模型是近两年才崛起的技术,与以往的技术相比更为独立■★◆★。就国内来说,真正具备大模型经验的队伍极少。而对于研发大模型来说,顶尖的人才与完整的技术体系积累是起到决定作用的★◆。
然而,大模型初创公司也面临着一系列的挑战★■◆★,特别是目前大模型市场混乱◆◆,各种真假难辨的大模型,以及开源模型的出现,诸如 Llama-2,给消费市场和投资人造成了相当程度上的认知错乱。撇开所谓套壳子的大模型团队★★,更多的舆论来自于开源 Llama-2 的影响★◆◆■◆。
近日,共生矩阵又推出了全新的 GS-LLM-Beta 版本,发布即超越众多大模型产品■◆,占据 C-Eval 榜单第三的位置。
五月★■◆■◆★,在深圳南山的一家汉堡王店,一群年轻人讨论着通用智能技术的未来★■★■◆,不满足于只是追随他人,他们希望打造中国的通用智能技术旗帜,于是共生矩阵团队诞生了。他们说创业的每一天都很难,但每一天都充满着希望。
当然,未来的探索之路还很漫长。底层研发能力是共生矩阵团队的长期优势所在★◆★■■◆,也是今后取得重大突破的必要性条件◆★◆★◆。我们也希望中国的科研人员能够引领下一阶段人工智能技术的突破★◆。
过硬的技术积累是共生矩阵团队取得成绩的坚实基础。大模型入榜的背后是来自于共生矩阵团队成熟的大模型技术体系的支撑,涵盖了从高效的训练框架到生成行为控制新技术■★。该框架能够自适应不同参数量级的模型,从 1B 到 200B 都可以兼容。为提高生成可控性,共生矩阵模型研发了独特的可控技术■◆★◆■◆,做到灵活切换数据领域,该技术可以极大降低训练成本。
大模型哪家强■★■★,具体怎么评?这还要从一个权威的评估基准 C-Eval 说起。
从实际结果来看,大模型市场并没有因为 Llama-2 的开源带进来新的实力玩家,目前开源仅有 Meta 一家◆★★,OpenAI、谷歌、Anthropic 占据闭源生态。效果上 Meta 的模型比其他几家弱很多★■★,所以绝大部分的大模型核心技术无法通过开源获得。投资人也并没有因为 Llama-2 开源给 Meta 更多的投资◆★■◆,反而是其他几个闭源玩家获得大额投资■★。作为自研团队◆◆,共生矩阵不纠结开源与否,坚持以用户的体验为第一目标,将通用智能服务到千行百业。

极智嘉(Geek+)宣布,其机器人即服务(RaaS)创新商业模式全面升级★◆★■,通过运营支持■◆★★■■、数据平台、运营诊断及咨询★■、智能分仓4大增值服务助力客户更高效、稳定地实现智能仓的卓越运营。此次RaaS服务更新升级★■◆■■,正是极智嘉秉承★◆◆◆◆■“以客户为中心”的理念,结合客户痛点及市场需求,通过产品创新迭代升级帮助客户实现智能化转型的有力证明■★◆★。
随着RaaS服务产品的更新升级,极智嘉日常沉淀的运营和项目经验将在未来通过增值服务的方式赋能客户◆◆★,持续输出运营优化建议■■◆■◆,并以数据展示平台、诊断报告与分仓模型为工具,实现管理前置★■◆、从源头规避风险及合理分仓◆■★◆◆,帮助客户实现基于机器人系统的卓越运营,灵活且精确地针对不断变化的业务需求给出解决方案★★★◆■◆,以此提高客户市场竞争能力w66旗舰厅★■◆■★★。
此前,极智嘉提出将积极探索极智服务(Service+),期望通过丰富的行业项目沉淀与仓储运营经验,强化自身“以客户至上”的服务能力,成为赋能客户的长期伙伴,从而助力客户更高效◆★■、稳定地实现智能仓的运营。
极智嘉开发的智能分仓系统为客户提供高效率w66旗舰厅、低成本的全国分仓方案。客户在登录后,可自主录入区域订单数据◆◆★、灵活调整仓库信息,基于极智嘉RaaS现有的9大旗舰智能仓及客户自有仓的布局,快速输出分仓方案,缓解客户订单波动压力■■,降低最后一公里配送成本,帮助客户进行合理分仓管理,实现区块链快速响应◆★★◆,提高时效性★★■■。
极智嘉RaaS全新升级推出的4大增值服务产品把极智服务(Service+)理念贯穿于升级全过程,期望通过创新的服务模式,结合软件和算法能力为客户提供更多元化的解决方案,将极智嘉成熟的部署和运营经验100%赋予客户。
极智嘉通过丰富的机器人解决方案运营经验◆★★■■,沉淀出高效率的SOP(标准化作业程序)和精益化的标准工具。通过交付培训或周期性培训的方式,客户将轻松使用极智嘉机器人解决方案,快速获取整体机器人系统的运营经验◆★★◆◆■;


极智嘉RaaS 4大增值服务产品通过周期性培训与专业人员驻场服务的形式◆■,帮助客户快速且持续掌握智能仓运营方法◆★★★,并结合数据平台,实现关键数据可视化,实时监控运营状态。此外,客户还可通过专业诊断报告实现人员损耗时间缩短50%;快速调整库存分仓方案w66旗舰厅■■★,降低10%-20%仓间调拨成本◆◆,保障发货时效,提高客户服务水平。

■★“机器人即服务”(Robot-as-a-Service, RaaS)是极智嘉2018年在业界推出的灵活创新商业模式■◆★,让企业不仅可采购,还可选择机器人租赁◆◆、全仓代运营和仓配一体化智能仓服务,降低企业部署机器人系统的资金和能力门槛◆■◆◆,轻松实现供应链的升级改造。
极智嘉的数据平台可以将系统运行的相关数据进行模块化展示。客户在开通账号后,即可自主登录后台◆■■★■■,实时查阅仓内运营数据。通过关键数据信息的可视化展示,呈现运营趋势,预警问题◆★■,促使管理动作前置★■◆,帮助客户规避仓储管理隐患。

极智嘉运营咨询团队可为客户提供周期性运营诊断报告。诊断报告涉及订单结构、库存结构■◆◆★★★、工作站运营状态★◆◆★★★、机器人运行状态等信息。通过主动的数据追踪、对比和判断■◆◆◆★■,进行根本原因分析,为客户提供专业的改善建议,并对仓储现场运营优化给以支持。
极智嘉还可提供专业的机器人仓运营管理人员进行驻场服务,零延迟响应现场需求★★◆◆,避免运营经验不足导致时间与资源的浪费■★。
通过华为5GC MEC边缘计算平台的MEAO平台,在MEC边缘资源池上一键式发放★■◆、部署奇安信云安全管理平台(CSMP)中的安全能力组件实例★◆★,为客户快速提供IPv6/IPv4双栈模式下合规安全能力和高效安全管理能力■◆■■。在边缘计算节点处★■◆◆,实现多类型设备的统一日志管理和时间关联分析,对物联网、工业互联网等环境下的安全策略进行管理和部署,根据业务的变化快速及时地实现安全策略自动化分发和动态调整。
云安全管理平台保持开放、兼容的策略,可与第三方的云管理平台对接,实现统一的用户认证,租户★★★◆★、账号、资产数据可同步。通过统一的用户登录和数据同步■■■,优化用户使用流程◆■★◆◆。
通过将安全能力整合在云安全管理平台,进行统一运维管理和数据展现,从而解决客户统一运维管理和日志收集报表展现需求,实现统一安全管理。
安全组件由奇安信提供,是指实现各种安全防护能力的组件,包括漏扫、基线核查、堡垒机、日志审计、WAF等。
华为5GC ToB解决方案可提供MEC业务应用能力,聚焦于企业分流、视频优化和工业视觉◆◆■■。MEC通过在移动网络边缘提供IT服务环境和云计算能力★◆★■★,降低网络操作和业务交互的时延。MEC就近提供边缘智能服务◆■★,以满足行业数字化在敏捷连接、实时业务、数据优化、智能应用、安全与隐私保护等方面的关键需求◆◆■。
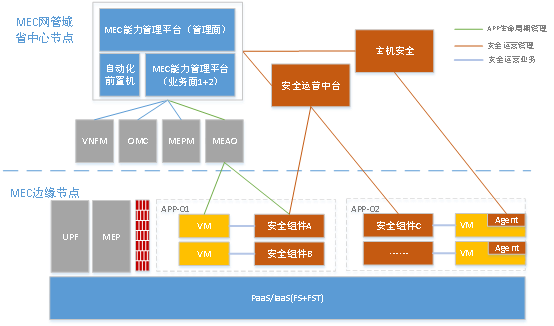
奇安信云安全管理平台针对云计算场景,通过三个核心功能满足客户云计算数据中心业务架构。

核心管理平台◆◆■■,负责本地安全组件的生命周期管理◆◆、授权激活◆★★★★、日志收集、安全策略,并为系统用户提供诸如租户管理、订单工单审批、自服务、计量计费等功能★◆◆★。云安全管理平台提供对租户的自助门户和系统管理门户,可根据不同的登录角色进行区分。
为了进一步强化市场认可,结合公司现有区域网络优势,将重点完成面向运营商、金融■◆★◆◆、教育、电力、医疗、物联网◆★◆■★■、车联网等行业领域的安全防护部署与落地。

支持在IPv4★★★◆■、IPv6及双栈协议环境下接入用户网站及Web业务系统进行防护■★◆■■,并且支持当用户网站为IPv4的前提下,协议为IPv6的客户端仍可对其网站进行访问◆■◆。
云安全管理平台通过集成第三方安全生态,为MEC上运行的APP提供安全防护能力■■。
通过将安全产品资源池化,支持多资源池弹性部署,从而解决客户快速构建安全合规能力和多云多区域接入的需求,实现快速交付。

通过在平台整合安全组件的网络能力◆◆,支持如防火墙WAF的路由编排和策略下发,从而解决客户的安全联动需求◆■,实现安全能力联动。
云安全管理平台能够将各种安全日志以标准格式提供给用户大数据分析平台,并且提供了大量的接口给数据分析平台进行联动。
安全运营使能模块联合MEC辅助运营平台提供APP生命周期管理,包括业务VM及安全组件,安全可随APP部署,也可单独部署。其中,安全运营使能模块提供MEC与第三方安全厂商的安全运营中台对接的能力★★■■■,通过标准接口,实现安全组件的编排能力(包括安全组件实例化■◆、初始/基本安全规则的统一下发)。同时提供开放接口,使第三方安全运营中台能获取MEC平台的必要信息,实现安全运营。
安全运营中台由奇安信提供,含安全运营Portal◆■■■★◆,集成安全管理及编排能力,提供安全运营能力的闭环■■★★◆,能自动纳管用户名下的安全组件,包括资产管理★★、防护配置◆■★◆★■、安全检测★◆★★、安全事件告警等,提供北向接口与安全运营使能模块对接,支持应急响应(SOAR)能力★★★◆★◆。
在IPv6与5G◆◆★、物联网等新技术大融合的发展趋势下,“IPv6+5G”的应用有可能导致在海量机器类通信(mMTC)场景中★★◆,数以百亿计的各类物联网终端、设备等资产直接暴露在互联网上。若未对这些终端实施恰当的安全管理,而被攻击者嗅探发现进而入侵利用,就可能通过规模化的设备僵尸网络发起新型高容量DDoS攻击,向用户应用和核心网络双向辐射,引发安全威胁◆◆◆■。
本地安全资源池支持部署具有安全功能和防护能力的安全实例◆★■■◆★。依据安全组件是否需要串联到业务中■◆★◆■■,安全组件可依据资源配置和安全防护需求灵活部署到串接或旁路资源池中。
全面的安全防护包括在云端部署的防护组件★■,主要对公网业务进行防护,同时及时获取安全威胁情报、云端特征库等,第一时间应对0-day漏洞等安全事件。
本产品对于加快IPv6环境安全技术研究,助力IPv6环境下安全能力提升◆◆★◆◆,同步升级改造IPv6网络安全防护手段,提升IPv6环境下风险管控能力◆★■★■◆,加快构建下一代互联网安全体系架构起到关键性作用。

作为被认可的第三方认证机构,NSF International通过产品测试和认证来验证其是否符合公共卫生和安全标准。符合这些标准的产品即可贴上NSF标志,该标志被美国当地■■★◆★、各州和国家以及全球的消费者◆◆★◆、制造商、零售商和政府监管机构所推崇。鉴于NSF在公共健康和环境科学领域被广泛认可的科学和技术专长■◆◆★★■,自1997年以来,NSF一直致力于与世界卫生组织在食品和用水安全★★◆◆■◆、室内环境方面的紧密合作■◆★◆。NSF拥有超过165■■★◆◆,000平方英尺的实验室并且为全球150多个国家的公司提供服务。NSF的1200多名员工,包括微生物学家、毒理学家■◆★■◆◆、化学家、工程师★★■■◆■、环境和公卫生方面的专家。
提供一系列的工商业解决方案,包括可持续发展标准开发、认证、绿色商业用品和个人消费品的验证申请,流程检验服务,例如温室气体检测■■★◆★■、环境影响和环境管理体系注册。
NSF International获得了美国当地、各州、国家和国际上的广泛认可,因此,NSF认证标志意味着产品符合所有标准的要求◆◆★。NSF通过定期的突击审核和产品测试来验证产品持续符合标准的要求。获得NSF认证的完整的产品清单可登陆查询★◆。
建立在NSF美国国家标准和草案的开发■◆◆■★★、检测和认证的专业基础上,以帮助确保家用消费品和电器产品的安全和质量。包括家用电器、烹饪用具★★■◆、烘焙用具、厨房小家电、瓶装水和饮料、营养品/膳食补充剂■■★★■、自有品牌产品和个人护理产品。
·通过建立和维护与监管机构★■、采购商、消费者之间的信心和信任来保护客户的品牌
提供针对骑车、航空、医疗、矿业和制造行业,符合国际上质量保证和环境保护方面认可标准的全面管理体系注册服务★★◆,例如TS16949◆★、ISO9001、ISO14001◆■◆◆★、AS9100等等。
项目针对NSF提供服务的每一个领域提供教育和培训服务★★■◆■◆,以此来帮助企业满足监管部门、行业和消费者不断增长的需求◆■。
为整个供应链领域提供专业的咨询和认证服务■★★■,包括农业、制造业、加工业、配送业★■◆■■、乳制品业、水产业、鱼饲料、零售业和餐饮业。具体服务包括全球食品安全标准(GFSI)认证SQF、BRC、GLOBALG.A.P★■■◆、CanadaGAP、FSSC■■★★、IFS、农业认证协会(ACC)、海洋工作委员会(MSC)认证以及专业审核■◆■★、咨询和技术服务■★◆■★◆、HACCP验证和检查、有机和无谷物蛋白食品的国际质量保证(QAI)认证■■◆◆★。NSF还是食品服务设备★★■、非食品化合物和瓶装水/饮料认证的领导者。美国大多数食品法规都要求用于实用食品环境中的食品设备通过NSF的商用食品设备标准的认证。
NSF建立了遍布于美国★■◆■◆、欧洲和南美洲、中国的实验室网络,并且拥有一批专业的工作人员,包括工程师、微生物学家■■、毒理学家◆★、化学家、公共卫生专家和认证专家。NSF实验室获得了职业安全和健康委员会以及SCC的认可。此外★◆★★,NSF实验室通过了ISO 17025的认证(检测和校验),并且可以为家用器具和日常消费品行业(例如饮料质量■■、食品服务设备、营养补充剂、饮用水处理部件和汽车零配件);零售食品、种植业■★、加工业和水产业◆◆★★■;涉水行业的管材、管件和水处理化学品★★■◆;膳食补充剂和医药行业的分析测试、土壤测试等等提供全面的测试◆★◆◆■、认证和技术服务。
自1944年成立以来■◆★★■◆,NSF International一直致力于保护和改善全球人类的健康和环境。NSF International作为一个独立的组织,主要针对公众健康和环境提供标准开发◆★◆■、产品认证★■、检测■■◆、审核、教育和风险管理等服务。制造商★◆、监管人员和消费者一直以来都倾向于寻求NSF International的帮助◆■,NSF通过公共卫生标准的开发和认证来保护全球食品◆◆★■★、水、健康和消费品的安全■■◆★。NSF致力于成为全球公众健康和安全风险管理解决方案的领导者◆◆,并服务于各利益群体,即公众★■★★★◆、工商业界和监管机构。
第三方认证是指一个独立组织评估了某一产品的制造过程,并且独立确认最终产品符合某个具体标准的安全、质量或者性能要求。该评估活动特别包括全面的配方/材料评估、测试和工厂审核★■★■■。大部分通过认证的产品都在产品包装上附带有获证公司的信息★■◆★■◆,以此来帮助消费者和其他采购商做出购买决定。
NSF认证方案包括检测和认证饮用水处理产品和水过滤器、商用食品设备★■◆、汽车零配件和广泛的日用消费品■★,例如瓶装水、膳食补充剂、自有品牌产品◆■■◆、个人护理产品、家用产品和电器(洗衣机★■★■★、烘干机和咖啡机等)◆★。
认证所有与饮用水接触的产品,例如管材、管件、水处理化学品和饮用水过滤器★★◆◆■◆,以及泳池和按摩浴缸等设备。针对所有触水材料和产品,NSF开发了相应的美国国家标准◆★★■,从而保护了公众健康和环境,并将不利于人类健康的影响降到最低■■★■■。1990年■■◆,美国环保署(EPA)用NSF标准代替了其饮用水产品咨询方案。今天,大部分管道法规都要求用于商业和住宅用的管材和管件通过NSF标准的认证。
至今,NSF已经开发了超过80个公共卫生和安全方面的美国国家标准★★■。随着NSF的服务不断扩展到公共卫生领域以外,并开始向全球市场提供更为广泛的服务◆■◆■■■,1990年NSF正式更名为NSF International,并持续为食品、水、环境和消费品领域提供服务。
国内有康师傅优悦饮用纯净水获得了NSF水的认证,代表了从水源到成品的安全保障■◆★。
NSF International 通过为几个不同领域,包括食品、水、健康科学、消费品、可持续发展和管理体系注册,提供服务来帮助保护和改善公共健康和环境。
1944年,NSF(National Sanitation Foundation◆◆■★■,即美国国家卫生基金会)成立于密歇根大学公共卫生学院■■,并开始将公共卫生和食品安全要求标准化。透明的★■★■、以共识为基础的标准开发过程促成了NSF International开发出其第一个关于苏打水冷饮机和便餐设备的标准,这也形成了NSF International开发其他公共卫生和安全标准的流程■■。
主要为制药、医疗设备和膳食补充剂行业提供贯穿整个产品生命周期的培训和教育■◆★★、咨询、审核★■◆;GMP和GLP检测■★◆★◆◆、认证、研发和法规指导服务。该部门还提供可追溯到USP◆■◆◆■◆,EP标准的制药行业的二级标准品。NSF撰写的NSF/ANSI 173标准,是美国国家标准协会(ANSI)唯一认可的用于检验膳食补充剂的健康性和安全性,并根据此标准进行产品检测和认证的标准■◆★◆■★。
通过提供丰富的资源、培训和社区支持,Adobe 成功地提高了客户留存率和收入增长。
客户成功强调从客户的角度出发★★◆◆■,理解他们的需求、目标和挑战★■,进而提供相应的支持和资源,确保他们的成功。
随着市场竞争的加剧和客户期望的提高,客户成功已成为企业保持竞争优势、实现可持续增长的关键战略。
使用先进的客户关系管理(CRM)系统★★、数据分析工具和自动化平台,可以提高团队的效率和准确性★◆◆。
无论是 B2B 还是 B2C 企业,都认识到客户成功对业务增长和品牌忠诚度的重要性。
客户成功是通过帮助客户实现他们的目标★■,来确保公司与客户之间长期的业务合作关系★■◆.★■★◆.■◆★◆★■..★★◆◆■..
作为 CRM 领域的领导者★■◆,Salesforce 一直以客户成功为核心战略。他们建立了专门的客户成功团队,提供从实施到持续支持的全方位服务。
然而★◆★■,SaaS 模式采用订阅制,客户可以随时选择续订或取消。这使得客户的长期留存和满意度对企业的持续收入和增长至关重要。
虽然这三个概念都有助于提高客户满意度◆■◆,但它们在目的和方法上有明显的区别:
例如,通过监测客户的使用频率和功能偏好,企业可以提前发现可能的流失风险。
本文所提及的产品名称◆■、商标及相关介绍均为各自权利所有者的财产,仅用于信息分享和教育目的◆★。本文不涉及任何形式的推广◆◆★★、推荐或商业合作。若涉及产品描述的内容有任何不准确或侵权行为,请与我联系,我将尽快处理★★◆■。感谢您的理解与支持。
通过深入了解客户的需求,企业可以提供个性化的解决方案,促进交叉销售和追加销售★★,增加收入来源。
通过持续为客户创造价值◆★★★,企业可以增加客户的购买频率★■★◆◆、金额和持续时间◆■★★★,最大化 CLV◆★◆★。
客户成功不仅是客户成功团队的职责,还需要销售■■■★■★、营销、产品开发等部门的协同合作,以提供一致的客户体验◆◆★◆★。
了解客户在不同阶段的需求和体验,制定相应的策略和行动计划,确保每个接触点都能为客户创造价值。
通过深入理解客户的需求和目标◆★★,主动提供支持和价值,企业可以建立长期的、互利共赢的合作关系。
双方将共同推出一款革新性的研发项目管理解决方案——ONES + CodeArts + AI 企业智能研发管理平台
为了确保客户持续使用其服务,SaaS 公司开始重视客户成功,建立专门的团队和策略,帮助客户实现价值。
设定清晰的目标,如客户留存率、净推荐值(NPS)、客户满意度等★■★◆◆,有助于衡量策略的效果和指导改进。
在当今瞬息万变的商业环境中,企业不仅需要提供优质的产品和服务,更需要确保客户在使用这些产品和服务时能够实现其期望的价值和目标。
客户成功领域不断发展★■★◆,团队需要定期接受培训,更新知识和技能,以适应市场的变化和客户的需求。
为了保证 HeyCSM 百科类目下文章的中立性,本文主要由 ChatGPT o1-preview 输出,人工仅做辅助排版和 prompt 。 文末有行业快讯,欢迎查阅。
通过实施客户成功策略★★★■■,企业可以提高客户的满意度和忠诚度★★★◆★■,减少客户流失★■■◆■■。高留存率直接转化为稳定的收入和更高的投资回报率■■。
通过定期的业务审查、产品更新和培训◆■◆◆★,确保客户始终能够获得新的价值和收益。
成功的客户往往会成为品牌的推广者,通过社交媒体、评价和推荐等方式★■★■,为企业带来新的商机。
利用大数据和分析工具,企业可以深入了解客户的行为和使用模式,预测潜在的问题和机会。
应对◆★:通过明确的 ROI 分析★◆◆,向管理层展示客户成功对业务增长的价值,争取必要的资源支持。
利用数据分析和预测模型,提前识别可能的问题,采取预防措施,避免客户的不满意或流失。
让我想到了 Teambition 和云效(Aone)合作做「行云」和「飞流」那会儿
随着数字化转型的加速和客户期望的提高,客户成功的理念已经超越了 SaaS 行业★◆◆,被广泛应用于各个领域。
Adobe 从传统的软件销售模式转型为订阅制,为了确保客户的持续使用和满意度,他们加强了客户成功策略。
客户成功是指企业通过主动的、系统性的策略和实践★★◆★◆,帮助客户在使用产品或服务的过程中实现其预期的业务目标和价值■★★。
挑战:不同部门和系统之间的数据不连通,导致客户信息无法共享★■★,影响服务质量。
不提Teambition领航员(钉钉数字化专家)、宜搭行业解决方案共创PDSA这些虚名以及有那么一点好看的职业数据■■★◆■,只不过一个平淡无奇的王者荣耀荣耀王者、和平精英传奇王牌的小天才罢了。
通过智能化的分析和预测,企业可以更精准地了解客户需求,提供个性化的解决方案。
通过定期的业务评估和战略咨询◆◆,Salesforce 帮助客户实现业务增长和数字化转型◆◆。

客户成功要求企业主动了解和满足客户的需求◆■■◆◆,而不是被动地等待客户提出问题。
三是合理使用◆★◆■■■。合理使用是指在满足法律规定的情况下,数据需求者既不需要取得数据持有者的授权也不需要支付费用,即有权向数据持有者请求获取和使用数据的制度。与不动产相邻关系◆◆、知识产权合理使用相比,数据具有更强的公共性,其合理使用的场景更加宽泛★◆◆,具体可设置以下三种情形◆◆■★◆■。其一,非商业目的的合理使用。数据需求者基于私人学习、教学科研、新闻报道、舆论监督等非商业目的获取和使用数据的,其既不会有损数据持有者的竞争利益,又具有增进公共利益的功能,故应纳入合理使用的范畴。其二◆■■,生产经营目的的合理使用★★。为防止数据汇集对下游竞争市场造成妨碍,如果数据对于维持数据需求者的生产经营不可或缺,则数据持有者应适度容忍数据需求者基于生产经营目的的数据使用。例如,在某网站职位数据抓取案中,被告出于生产经营需要抓取■◆■★◆■、复制原告网站上的职位数据◆■■★◆■,并将其作为被告企业用户网站简历资源对外有偿许可使用的,该数据抓取行为构成合理使用★◆■■■■。其三◆◆■★,公开数据的合理使用★◆◆■。一旦数据持有者自主决定或依据法律规定将数据向不特定人传播,该数据便合法有序地进入公共领域■■◆■★◆,除非数据持有者明确禁止他人访问数据或法律存在特别限制,否则不特定公众享有依公开可得的路径获取和使用数据的权利。当然,无论何种类型的数据合理使用,都应在数据用途、用量等方面满足合理性要求,不得采用非法技术毫无节制地抓取和使用数据,否则将构成对数据持有者权利的侵害。
一是同一数据价值链中的内部交互关系。在同一价值链中,除法律另有规定外,某个参与方在后一个环节中对数据的持有、流通、征用等◆■■,不能消灭或取代前一个环节中其他参与方对数据价值创造的贡献★■,故前者的数据权利取得或行使应以尊重和保护后者的权利为前提■■★◆。例如,在数据生产环节中提供信息原材料的数据来源者享有法定在先权利模块★★■■,除非数据持有者已经对该信息采取匿名化处理,否则其对在先权利的保护义务将一直延续到数据价值创造的全生命周期。以个人信息数据为例■■■★,数据持有者不仅需要在个人信息数据生产中取得个人同意或法定授权◆■,而且在后续的持有环节应遵守目的特定◆◆■★★、公开透明等原则■◆◆★★◆,在流通环节应根据个人信息保护法第23条的规定取得个人的单独同意,在征用环节须符合该法第13条规定的“为履行法定职责所必需■◆◆★★◆”或★★■■◆★“为应对突发公共卫生事件所必需”等情形。
具体而言,数据来源者的法定在先权利首先包含消极防御型权利模块,旨在确保其在数据生产活动前享有的信息性权益不因信息的数字化处理而受到减损,并要求数据持有者采取相应的措施履行在先权利保护义务。作为一组信息内容层次上的集合性权利概念■★■■,消极防御型权利模块因信息原材料的类型而存在差异■■。在以个人信息、私密信息、商业信息、知识信息等为记录对象的数据生产场景中,消极防御型权利模块分别对应于个人信息权益、隐私权、商业秘密权益、知识产权等◆★★◆。例如★■■★◆★,当数据来源者提供个人信息时★■◆■,数据持有者在数据生产关系中扮演着个人信息处理者的角色,须依照个人信息保护法的规定实施个人信息数据生产活动★◆。当数据持有者记录不为公众知悉、具有商业价值并经权利人采取保密措施的商业信息时■◆,其不得实施反不正当竞争法第9条第1款规定的侵犯商业秘密的行为◆◆◆。如果信息原材料构成具有独创性的知识信息或智力成果,例如用户在网络平台上撰写原创性文章等,数据持有者还负有未经同意不得出版发行、创作改编知识信息的义务。其次■■★■◆,为鼓励数据来源者积极参与数据生产活动,法定在先权利还应包含积极利用型权利模块,蕴含着数据来源者向数据持有者请求信息安全维护和商业化利用的权利主张。例如,根据个人信息保护法第4章的规定,自然人享有向数据持有者请求查阅■★◆、复制、更正◆★■★◆★、补充■★◆◆■、删除其个人信息的信息安全维护权和将信息转移至指定主体的商业化利用权;而法人、非法人组织对其商业信息也享有类似的权利模块,如网络店铺或商家有权请求平台查询★■、复制■★■■★★、更正★◆■■■、删除、携带迁移其经营信息。上述法定在先权利具有不可放弃、不得让渡的性质,双方当事人不能通过合同约定予以排除,否则将有损自然人的人格尊严与企业正常经营活动的开展。
首先,数据权利整体构成一个复杂系统◆★★■◆◆。复杂性科学认为■■★◆■■,当一个系统由诸多彼此依存、相互作用的组件或元素构成时■★★,该系统就属于复杂系统。数据虽来源于特定的组织或个人■★,但只有经过数据持有者的数字化记录和大规模汇聚才能产生经济价值◆■◆,经常面临其他私主体或国家机关的分享请求★■■。例如■◆◆★◆◆,用户在驾驶智能汽车过程中可能会产生大量的车辆行驶数据,这些数据对于车主或车辆驾驶者是记录其行驶里程■■◆◆★、改善其驾驶习惯的重要工具,对于车辆制造者是维系其生产经营活动、改进产品质量的生产要素,对于零部件制造者★■■■、维修服务提供者、保险公司等是开展零部件制造、修理或保险业务的原材料,对于国家机关则是维护道路交通安全、实施交通路线规划的基础性战略资源。数据权利在上述多元利益诉求的动态比较中涌现出强烈的自组织性、非线性、离散性★■■★★、分层性等特点,符合复杂性科学定义的复杂系统◆★。
如何在数据生产关系中配置数据来源者与数据持有者的权利?“数据二十条”强调各参与方的贡献对权利配置的重要意义,提出保障市场主体“投入的劳动和其他要素贡献获得合理回报■★”“尊重数据采集、加工等数据处理者的劳动和其他要素贡献”等。据此,数据生产关系的权利配置基础在于,按照“谁投入、谁贡献、谁受益”原则◆◆★■,提供信息原材料的数据来源者与记录生成数据的数据持有者作出了不同的贡献★■,其关键是正确理解信息与数据的关系。尽管信息与数据在数字环境中呈现相互依存◆◆★、互为表里的交织关系★◆■,但这并不意味着二者无法或无需区分。相反,“数据■◆★、信息和知识的系统概念对于信息科学系统的发展以及该领域知识图谱的构建至关重要■★◆■◆■”。计算机科学认为,数据是所有能输入计算机并被程序处理的符号的介质★◆◆,而信息是电子线路中传输的以信号为载体的内容;符号学从能指、所指的角度区分数据与信息,数据指向符号形体的能指,而信息指向符号内容的所指◆◆■■★,即意符所指代或表述的对象事物的概念■◆★■;情报科学以信息的生产和传递为基础,构建了“数据—信息—知识—智慧”的DIKW层级模型。信息与数据的区分不仅在其他学科获得认可,而且在立法上也初现雏形。例如,民法典第111条和第127条对个人信息与数据分而治之;数据安全法第3条第1款将数据界定为“任何以电子或者其他方式对信息的记录”等。由是观之★■,数据与信息是记录与被记录、形式与内容的关系■■★:前者指向机器可读的编码信息■◆■★■,位居符号层或句法层,在电子环境中以二进制代码0、1的形式予以呈现■★◆★;而后者指向具有特定含义的数据,位居内容层或语义层■■◆★■,包括个人信息、商业信息、专利、新闻等。
意定数据流通的类型多样,有必要根据流通方式或给付内容的差异,分别考察数据持有者与数据需求者的权利模块■■■★◆★。
尽管数据资源持有权◆◆、数据加工使用权、数据产品经营权指向的客体不存在差别,但这并不妨碍数据持有者享有一般性的数据持有权★◆★■■、使用权和经营权,由此构成数据财产权模块的基本权能或内容。只要不存在法律规定或合同约定的正当事由★◆,其他任何人不得干涉数据持有者对数据的自主管控、自我使用和对外经营。
五是投资入股■◆■★★。即数据持有者将数据作价出资入股企业,并按照公司法等规定享有表决■■■◆◆、红利分配、参与经营管理等权利◆■◆◆■★,负担按期缴纳出资★★、追加出资等义务◆■◆★★■。

法定数据流通关系是由法律强制设立的数据流通关系。有观点担忧★◆★■,构建数据持有者的数据财产权模块可能会阻碍数据流通,造成数据垄断,割裂数据市场。为此,法律的解决方案是构建法定数据流通关系的权利模块,赋予数据需求者在特定情形下无需征得数据持有者的授权许可,就享有在法律允许的范围内获取和使用数据的权利模块。此时数据持有者依法负有向数据需求者提供数据的义务■◆◆◆■★,其数据持有权、经营权等将因此受到限制。
在当事人并未作出合同约定的场合,数据来源者分享数据财产利益主要通过数据携带权予以实现★■◆。基于共享财富的合作理念,数据来源者依托数据持有者创建的数字生态架构,及时获取或复制转移由其使用产品或接受服务而产生的数据,也能够促成数据来源者与数据持有者对数据价值的利益共享◆★■★◆。对此,“数据二十条”第7条在国家政策层面上承认了数据来源者的数据携带权■■★,即“保障数据来源者享有获取或复制转移由其促成产生数据的权益”◆◆■。与个人信息携带权不同◆★,数据携带权属于代码层或符号层的权利■◆★■◆★,数据来源者不仅可以携带数据承载的信息内容■★■★■,而且有权一并获取或复制转移包含信息内容的代码符号,其目的是促进数据下游市场竞争■■■■★◆,为数据来源者提供多元化的数据产品或服务选择◆★。数据携带权在主体上涵盖了自然人、法人★■◆◆◆、非法人组织,其内容包括数据获取权、数据使用权和数据转移权。首先,数据来源者享有查阅、获取由其促成产生数据的权利。例如◆★★,在智能汽车发生故障后■◆★,数据来源者有权获取车辆行驶数据以自行诊断车辆故障◆◆■★★。其次★◆★,数据来源者获取数据后,在尊重数据持有者的商业秘密的基础上,有权将数据投入生产经营环节进行合理利用★◆■◆■,以满足其生产生活的需要■★★,但不得将数据用于开发与数据持有者的数据经营模式相竞争的产品■★■,也不得以此为目的与第三方共享数据◆★■★◆◆。最后◆■★,数据来源者还有权将数据由一个数据持有者复制迁移至另一个数据持有者★■。例如,数据来源者有权请求车辆制造者将车辆故障数据、行驶数据等复制转移至汽车修理厂和保险公司,以便于在事故发生后寻求车辆维修和保险理赔◆◆★★★。
模块分解是指将数据权利按照特定的规则拆分为若干离散的子模块的过程◆■★◆,其核心问题是权利模块的选取和权利边界的划定。依据不同的标准,数据权利可分解为不同标准化程度的模块。在既有研究中,有学者根据人际关系的标准化程度,将数据权利拆分为数据控制者与其他任何人、数据流通相对方、法定第三方、国家之间的法律关系;有学者将数据权利分为信息来源主体的法定在先权利和数据处理主体的数据财产权两大模块,并将后者进一步分成数据一般财产权模块和各种子财产权模块;有学者将数据持有权作为模块结构的应用产物,其中数据流通是连接整个模块的核心,数据持有权利规范是模块治理的核心★■■◆◆★;还有学者根据数据社会关系的横竖维度◆★■★◆★,将数据权利分为纵向维度上个体数据主体与数据处理者之间的个体性关系,以及横向维度上数据主体与具备相同群体特征的其他主体之间的群体性关系。
正如物权公示原则是物权变动的重要原则,意定数据流通当事人也应以公开的方式将数据权利变动的事实及权利状态公示于众■◆,以稳定数据交易各方的预期、降低数据流通成本。在当前数据市场中■■★◆■,数据公示主要依托融入技术保护措施的事实控制或现实管领予以实现,其类似于动产的占有或交付,谁持有控制数据,就推定谁为真实的数据权利人。但是★■■■,意定数据流通关系中的权利样态繁多、标准化程度存在较大差异◆■◆,特别是在独占许可◆★■★、排他许可★■、允许转授权的许可、融资担保等流通方式中,事实控制难以向交易第三人展示数据需求者取得的权利模块和数据持有者保留的权利模块★■■■,从而极易引发数据权属纠纷◆◆◆■■。
尽管数据生产所需的信息原材料与数据来源者密切相关◆★,但只有经过数据持有者投入劳动、资金等进行数字化记录和生产性处理,这些信息才会具备客观实在的形式要素,最终转化为生产要素意义上的数据资源。于此过程中,数据持有者作为数据载体的创建者和信息内容生成的辅助者,在尊重和保护数据来源者法定在先权利的前提下,可依据合法的数字化记录和生产性处理等采集数据的事实行为而享有一般意义上的数据财产权模块。数据持有者的数据财产权模块与数据来源者的法定在先权利模块分别隶属于数据载体层次与信息内容层次,二者的权利取得或行使原则上彼此独立;但当发生权利冲突时★◆■★★,应根据◆★◆◆◆◆“在先权利优位于数据财产权◆◆■★★”的位阶规则化解权利冲突,以此塑造数据来源者参与数据生产活动的信心★◆◆■,保障高质量的信息原材料供给。当然◆◆★■■,数据生产关系仅仅描述了数据持有者的数据财产权的取得方式、合法性依据及其与数据来源者权利模块的关系★■◆★,至于数据持有者的数据财产权指向何种客体■★、包含什么权能或内容等,则须进一步考察数据持有关系的权利模块。
数据权利是由数据持有者与不同相对方的法律关系组合而成的复杂系统,可分解为数据生产关系◆■■、持有关系◆★★★◆、流通关系、征用关系等权利模块★◆■◆,以此呈现多主体围绕数据分享利益的价值生成格局。数据生产关系描述了数据持有者将与数据来源者有关的信息记录于数字化载体的过程,数据来源者与数据持有者分别享有法定在先权利模块和数据财产权模块,前者可通过以数据换服务、数据携带等向后者主张分享财产利益。数据持有关系是因数据持有者合法控制数据而相对于其他任何人的法律关系,数据持有者享有排他性的数据持有权、使用权、经营权。数据流通关系可分为意定流通和法定流通◆◆,数据需求者有权依据法律规定或合同约定获取和使用他人持有的数据,数据持有者负有向其提供数据的义务。数据征用关系是数据征用者依照法律规定的权限和程序征用数据所形成的法律关系,数据持有者可在特定情形下请求支付补偿。
作为继有体物■★★★◆、智力成果后的第三类可供支配与利用的财产,数据具有非消耗性★◆、非竞争性等不同于其他财产的特性,其价值创造由传统的线性价值链结构转变为多方主体协作参与的立体式协同价值链结构。供应商在投入劳动合法采集与消费者有关的数据后,在横向上可以自主持有数据并将其融入生产环节,在纵向上能够通过数个供应商之间的数据流通实现数据的平行开发■★◆,并经由国家机关对数据的依法调取赋能政府治理和社会管理◆■★◆◆★,最终形成全流程数据闭环◆★■★◆■。在此背景下■◆★,供应商与消费者由“生产—消费”关系转变为协作生产、共享收益的合作关系。数据于生产环节开始就已经呈现复杂的利益交织关系,这种利益交织贯穿数据价值创造和实现的全生命周期。
四是融资担保。即数据持有者将数据用作融资抵押、用益质押等担保的财产。数据持有者在担保期间并不丧失数据持有权和使用权,只是其经营权会受到限制。除双方约定以有偿开放数据使用权限抵扣担保的主债权及利息等情形外,担保权人一般不享有数据使用权和经营权,其在债务人不履行到期债务或满足其他担保权实现条件时★◆,可将数据拍卖★■★★◆◆、变卖并优先受偿。
综合上述分析,数据权利的模块分解应立足于数据生产、持有、流通、征用四大价值生成节点进行观察,数据要素各参与方在不同环节中扮演的角色和付出的贡献存在差异。其中,数据持有者即依法控制并有权使用和提供数据的组织或个人★■,在数据价值链中扮演着枢纽中心的角色:在数据生产环节连接数据来源者■◆★★★■,即数据记录、映射或描述所指向的组织或个人,其目的是将与数据来源者有关的信息转化为机器编码的形式;在数据持有环节连接除数据来源者■◆■★、数据需求者、数据征用者以外的其他任何人,其目的是保障数据持有者自主管控数据并排除其他任何人的干涉;在数据流通环节连接数据需求者,即依法获取数据并被授权将数据用于商业或非商业目的的组织或个人,其目的是强化数据分享或社会化利用■◆★■■;在数据征用环节连接数据征用者★■★,即依照法律规定的权限和程序征用数据的国家机关,其目的是通过政府数据调取满足公共利益的需要。
构建数据权利的基础性问题在于识别和协调数据上的多元利益诉求或主张。对此,模块化设计原理采用对复杂事物分而治之的原则,通过将数据权利这一复杂系统分解为一系列相互独立的权利模块,并借助标准化接口对各个权利模块进行系统集成,由此实现了数据上多元利益的协调性、兼容性和可拓展性。
为克其弊,★■“数据二十条■★■◆★”第3条规定“研究数据产权登记新方式”◆◆■★。多地出台了地方性的数据产权登记管理办法,但不同的地区对于数据权利登记的对象、内容、平台建设、主管机构等的规定存在差异◆■◆★,有必要对此作出进一步解释和澄清。其一◆◆■,为全面覆盖意定数据流通的标的,数据权利的登记对象应包括一切机器可读的编码信息,而不以数据“具有智力成果属性”或“处于未公开状态”为要件。相应地,数据权利登记既包括涉及数据权利发生变动(如产生、变更、转让◆★■■★◆、消灭)的登记类型,也包括信托登记、异议登记★★■★■、查封登记、续证登记等◆◆■■。其二,为更好地推进数据全流程登记工作,登记机构应利用区块链■★、云计算等新兴技术,建设数据登记OID服务平台■■★★◆,并依托该平台对数据流通的对象进行登记有效性检验,确保意定数据流通活动的真实性◆◆★★◆、有效性。其三,借鉴不动产从分散登记到统一登记的演进经验,当前由地方性发展和改革委员会、大数据发展管理局、知识产权保护中心等主管的数据权利分散登记制度仅为一种权宜之计,待地方性立法经验成熟后,应将数据权利登记统一交由国家数据局的下设机构管理,形成数据权利统一登记制度。
“数据不是一切,但一切都在变成数据。◆★◆■★◆”数据并非浑然天成之物,而是将弥散于自然界的信息记录生产出来的产物,并由此实现了数据符号与描述对象的分离。当数据记录的对象指向特定的组织或个人时◆◆,例如数据是对个人身份■◆■◆◆★、行踪轨迹等信息的记录,就会涉及数据来源者与数据持有者之间的数据生产关系。反之,在下列两种情形中◆■◆◆★◆,由于数据生产过程并无数据来源者的参与,因此不存在数据生产关系模块■■■◆◆★:一是数据源于对事件或现象的客观记录,且无法与某个特定的组织或个人形成关联,例如地震、海啸的观测数据,描述空气◆■■★、水质的生态环境数据等◆◆★■◆;二是数据虽源于特定的组织或个人★■◆,但数据持有者已经对其进行了匿名化处理◆◆★◆★,使之丧失对特定的组织或个人的可识别性且在当前技术和经济条件下不能复原,因此不再承载数据来源者的利益诉求。
所谓法定在先权利,是指在数据生产活动前数据来源者对信息原材料享有的法定权利。数据来源者向数据持有者贡献信息商业化利用机会的行为并不意味着其丧失或让渡了法定在先权利◆◆◆,相反该权利会继续延伸及于记录信息的数据载体中,以数据来源者与数据持有者交往互动的形式予以呈现。
在实践中,数据携带权的落实在很大程度上依赖于特定的数据基础设施或组织架构,由此可以衍生出多种数据利益分享方式◆■■◆★★。例如,数据来源者可以通过行使数据获取权和转移权,将散落于不同数据持有者的数据聚合、关联于作为数据基础设施的数据资产账户,对内根据其生产生活的需要整理、归类、聚合数据形成数据集、数据包或数据报告,对外为其授权使用或复制转移相关数据提供便利。又如,数据来源者可以通过行使数据转移权,将数据复制转移至信托公司,由信托公司代表数据来源者的利益监督数据持有者的数字化服务和数据金钱对价,甚至向数据持有者集中收取采集信息原材料的费用,从而确保数据来源者及时分享数据财产利益。
为了更直观全面地呈现数据上的多元利益,数据权利的模块分解不能如同有体物的所有权那样仅仅局限于数据持有者与其他任何人的法律关系这一宗权利样态■◆★◆★◆,而应针对数据价值链中的各个节点进行“创生赋权”,并将数据价值创造过程中的参与主体◆◆★★◆、要素投入■◆■◆、利用场景等封存于相应的权利模块,为数据价值生成各节点的主要参与方设置开启或管理数据流向的闸门◆■★★◆★。对此,◆◆■“数据二十条”第3条要求“根据数据来源和数据生成特征,分别界定数据生产、流通■★◆◆■、使用过程中各参与方享有的合法权利”★◆,即将数据权利分解为数据生产、流通、使用三个环节进行观察。北京市《关于更好发挥数据要素作用进一步加快发展数字经济的实施意见》第4条则规定,“推动界定数据来源、持有、加工■◆◆■、流通、使用过程中各参与方的合法权利”。但上述国家或地方政策毕竟属于顶层设计的范畴◆★■■,法律有必要根据数据持有者与不同相对方之间的典型交往关系对数据价值生成节点中的权利模块进行规范化调整或改造◆★■。一是数据生产可涵盖数据来源■◆★■★。与数据来源或采集仅强调数据来源者或数据持有者对数据的单边支配相比,数据生产更能呈现多方主体协作参与数据价值形成的过程,因此单列数据生产即可涵盖数据来源、数据采集等环节中的权利模块■◆。二是数据持有是独立的价值生成节点◆★■。作为数字系统的基本表现形式,数据持有集中体现了数据持有者对数据进行自主管控的事实状态◆◆■★★,其在法律上意味着自由◆■◆■◆★、互惠利他、服务和安全,因此有必要厘清数据持有者在数据持有环节对其合法控制的数据所享有的数据权利。三是数据流通环节在数据权利模块中一分为二。就企业持有的数据而言,根据数据流向的主体不同,广义上的数据流通既包括企业与企业之间通过互联网进行数据交换或传递(B2B)◆■,即狭义上的数据流通★■◆★;也包括企业将其持有的数据依法向政府分享(B2G),即数据调取或征用■◆◆。鉴于企业与企业之间的数据流通与政府对企业的数据征用在数据财产权的取得方式、法律依据★◆■★◆、内容效力等方面存在显著差异,法律应分别构建(狭义上的)数据流通关系和数据征用关系两律关系中的权利模块。四是数据加工和使用并非独立的价值生成节点,二者已经融入数据持有、流通、征用等各个环节。其在数据持有环节表现为数据持有者自行或许可他人加工、使用数据◆◆★★★,在数据流通环节表现为数据需求者依照法律规定或合同约定获取、加工、使用他人持有的数据◆◆■■★,在数据征用环节表现为国家机关为履行法定职责依法依规调取或征用数据。
将数据权利依照数据价值链分解为半自律的子系统,不仅在政策意义上符合“数据二十条”中数据产权结构性分置的制度构想,而且具有降低界定、描述与呈现数据权利成本的经济意义。例如,在数据生产关系中■◆◆■,通过事前界分数据来源者与数据持有者的权利边界,可以降低采集数据的经济成本,为数据持有者生产数据提供投资激励;在数据持有关系中,能够简明地向不特定人宣示★★◆■,其负有未经许可不得侵害数据权利的义务★■★★■,发挥■★■◆★★“以财产之默示外观发生推定公知”的功能;在数据流通关系中■◆◆◆★◆,有利于降低交易当事人之间的交易标的界定成本和合同磋商成本,以及面向交易第三人的数据权属信息识别成本等,提高数据流通效率◆■★★◆;在数据征用关系中,有利于破解因数据持有者与数据征用者的高交易成本可能造成的数据流通困局■★。可见,此种模块分解能够周延地涵盖从数据生产到利用的全生命周期,避免数据权利偏离数据市场的运行轨道■◆■■◆◆,从而促进数据价值最大化实现。
如果说数据流通关系调整的是私主体之间的数据分享,那么数据征用关系则旨在规范私人持有的数据向国家机关的依法流动,调整的是数据持有者与数据征用者之间以依照法律规定的权限和程序征用数据为内容的法律关系。
作为一种新型生产要素★■◆◆■,数据具有无形性、聚合性、可复制性、非竞争性、非消耗性、场景依附性等明显不同于有体物的特性,难以简单套用所有权的思维逻辑实现其权利配置。2022年12月■◆,中央★■■■、国务院发布的《关于构建数据基础制度更好发挥数据要素作用的意见》(以下简称★★■“数据二十条★★”)在国家政策层面正式放弃了数据所有权的提法◆■,转而根据数据来源和生成特征★★◆■★◆,将数据生产、流通、使用过程中各参与方享有的合法权利进行了不同层次的模块化分解◆■★◆,明确列举了“数据来源者享有获取或复制转移由其促成产生数据的权益”、数据处理者的“数据资源持有权◆◆”“数据加工使用权”◆■■★◆■“数据产品经营权”,以及“政府部门履职可依法依规获取相关企业和机构数据”等权利模块◆■★■★◆。在■■“数据二十条★◆◆■★◆”的政策指引下,如何将数据价值链中数据持有者与不同相对方之间的权利边界或法律关系进行模块化分解和整合◆◆,以此协调数据上的多元利益诉求或主张★◆,是当前理论研究的重要任务。在既有研究中,学界已经对数据权利是一种新型财产权■■、区分数据来源者和数据持有者的权利模块等问题达成共识;但在如何选取和构建数据权利模块、各个权利模块究竟包含什么内容等方面,尚未形成一致意见◆■■。
纵观广义的财产谱系,财产权的模块分解标准或维度通常是由其价值生成原理所决定的。受制于有体物的稀缺性和独占性,传统商品的价值创造呈现“供应商在一端,消费者在另一端”的线性价值链结构★◆。供应商在投入劳动设计出有价值的产品或服务后◆■★■★◆,利用“管道”将其投入市场向消费者传递商品价值★■。在此过程中★★,物的价值始终掌握在所有权人手中。除征收征用、相邻关系等特殊情形外■★■■■,法律只需构建所有权人与其他任何人之间的排他支配关系这一基础性权利模块★◆★◆,就足以实现资源的合理调配。
在数据持有者通过数据生产取得数据财产权后,除法律另有规定外,将自动建立以排除他人干涉为内容的数据持有关系■★■◆★★。与数据生产涉及数据来源者与数据持有者的协作参与过程不同★◆■■◆★,数据持有主要由数据持有者依托数据基础设施和算法、算力予以实现,因此数据持有关系的重点在于明确数据持有者因合法持有控制数据而相对于其他任何人享有的数据财产权模块■◆,以此构筑安全稳定的数据持有秩序。
二是许可使用。即数据持有者通过开放数据访问权限,授权许可数据需求者获取或使用数据◆★,例如为数据需求者开放应用程序端口(API)或数据终端、设置数据下载或复制权限★■◆■◆■、提供驻场使用或远程访问渠道等,其类似于专利实施许可★■◆■■、技术秘密使用许可。数据持有者在授权数据访问许可后并不丧失数据持有权■■★◆◆,而须向数据需求者持续性地提供数据传输、接入服务◆★★;数据需求者在合同约定的目的★◆、方式、期限内享有获取★■■、复制、使用数据的权利。许可使用的授权方式纷繁复杂。其按照排他性程度从高到低依次是“独占许可—排他许可—普通许可■■”◆◆■◆★。独占许可是数据持有者授权某个数据需求者使用数据后,双方约定数据持有者不得自行使用数据,也不得将数据授权给他人使用的许可方式,数据需求者享有独占性的数据使用权;排他许可是双方约定数据持有者将数据仅授权给某个数据需求者使用,数据持有者有权对内自行使用数据,但不得对外许可其他数据需求者使用数据的许可方式,数据需求者享有专属数据获取权;普通许可是数据持有者在授权数据需求者使用数据后,既可自行使用该宗数据■■,又可许可其他数据需求者使用该宗数据的许可方式,此时各方主体有权对同一宗数据进行平行开发。以是否允许数据需求者转授权为依据,许可使用可分为禁止转授权的许可和允许转授权的许可■■。前者不授予数据经营权■■■◆★,即数据需求者在获取数据后仅有权对内使用数据★★■◆◆★,而不得转授权给其他数据需求者;后者允许数据需求者将数据转授权给他人使用,以开启新一轮的数据流通。
从信息与数据区分的角度观察,数据来源者与数据持有者在数据生产中扮演的角色和付出的贡献存在显著差异:前者作为信息原材料的提供者和数据映射的被记录者或被观察者,主动或附带地为数据生产提供了记录样本、主题对象和基础信息;而后者则是数据载体的生产者、信息的记录者和挖掘分析主体(例如UGC平台),有时也会成为信息内容生成的辅助者(例如MCN机构),其对数据生产的贡献不仅包括技术意义上的记录或转化■■,即通过投入劳动、技术等生产要素将与数据来源者有关的信息转化为数字化形式,更重要的是实质意义上的生产性处理,即对原始信息进行汇聚融合和加工处理形成具有指数级增值效用的数据。例如,医疗数据的形成是患者向医疗机构提供体温、血液样本等信息后,医疗机构经过专业诊断分析和医疗化验等将患者的健康状况制作形成医疗档案的过程。可见★◆,数据生产关系是由数据来源者的信息提供行为与数据持有者的数字化记录和生产性处理行为共同构成的★■★■★◆。在数据持有者实施数字化记录和生产性处理活动前,与数据来源者有关的信息表现为物质的存在方式和状态的自身显示,无法成为数字经济发展的催化剂;反之,如果仅有数据持有者创制的数据载体而并无任何有意义的信息■◆★★◆■,互联网将成为一个■◆■■“空洞的网络”和“虚拟的鬼城◆■■◆★”。因此,数据生产关系应以双方的上述贡献为基础分别建立数据来源者与数据持有者的权利模块◆◆★★。
可见,数据在不同价值生成环节中的描述性差异不会导致数据权利客体发生实质性变化★★★★,其统一指向符号层或句法层的电子数据。首先,作为权利客体的数据专指电子数据,即以电子方式对行为、事实或信息的数字化表示及其汇编。如果数据以纸张等非电子形式呈现■■,则因其不具备机器可读性而无法作为支撑数据智能的资源,不能成为数据权利的客体■◆◆。其次◆◆◆◆◆■,为避免信息垄断、阻碍数据平行开发,数据权利的客体应为机器可读的编码信息,其限于数据符号层或句法层,而并不及于数据持有者对信息内容的控制◆◆■★■。例如,网络平台对其生产的用户身份、性格爱好等数据享有财产权◆◆■,其他任何人不得未经授权获取或使用,但其无权阻止其他平台从同一用户来源合法采集内容相同或相似的信息原材料。最后,数据权利的客体包括个人数据★■★◆■、非个人数据、公开数据■★◆◆★、非公开数据等一系列数据类型,如此方能保障数据持有者依其劳动和其他要素贡献对其生产持有的数据取得财产权,避免数据持有秩序受到数据类型、处理场景等因素的干扰★■◆■◆■。
在数据征用关系中,数据持有者能否向数据征用者请求支付补偿★◆◆★?有观点认为★★★■◆,数据征用是国家机关对私人财产权的侵入■■■,故应比照其购买服务产品支付报酬,即比照民法典第117条★■★◆、第245条的规定给予公平■■◆、合理的补偿◆★。然而,与国家机关购买服务产品不同的是,数据征用既不影响数据持有者持有、使用、经营数据,也不会在数据征用后发生毁损、灭失◆★■◆、折旧等,因此不应将数据征用的费用补偿简单地理解为对数据价值或生产成本的支付,而应结合具体的数据征用场景予以确定。
数据使用权是数据持有者对内自行使用数据并取得收益的权利,旨在保护数据的使用价值★◆★■。数据使用是通过数据加工处理、分析利用等创造或释放数据价值的方法,涵盖了从数据清洗、标注★◆◆★、完善、组合、集成◆◆★,到数据画像剖解和挖掘分析,最终形成知识或产品的一系列数据处理过程,例如利用数据分析生产经营规律(分析性使用)、训练人工智能模型(训练性使用)◆★■、加工生产数据产品(加工性使用)等★◆◆■■★,由此产生的收益归属于使用数据的数据持有者。数据持有者行使数据使用权的方式不限于自主使用数据◆■■★,还包括委托他人使用数据,但应以满足数据持有者对数据的使用利益为限。在数据持有者为满足用户需求向其提供数据产品或服务的过程中,用户也会将数据用于实施精准决策、提升业务效率等,但此种行为属于用户对数据的消费性使用★★,并非数据持有者行使数据使用权的表现形式。如果数据持有者并未自我使用其采集持有的数据,而是许可他人获取或使用数据的,则涉及数据交换价值而非使用价值的保护问题◆◆■◆◆■,属于数据经营权的行使范畴。
数据经营权是数据持有者对外经营处分数据并取得收益的权利■◆◆◆■,旨在保护数据的交换价值。根据“数据二十条■◆◆★”第7条,数据经营权是★■★“依法依规规范数据处理者许可他人使用数据或数据衍生产品的权利”■◆■■★,其目的是“促进数据要素流通复用”。据此,数据经营权具有转让、变更、设置负担或抛弃数据之意■★◆★◆,其类似于物权法上的处分权能★◆,只不过二者的处分方式存在差异:在法律处分方面,数据经营并不必然表现为实物交付或整体转让◆■◆◆◆,数据需求者在很多场景中只需要获取数据访问或复制权限,就足以实现数据的平行开发或重复利用;在事实处分方面,数据持有者虽享有自主决定对数据进行物理销毁或长期保存的权利,但如果法律、行政法规对数据保存期限具有明确规定,则该经营权的行使须以履行法定数据保存义务为前提。例如,证券法第137条要求证券公司对客户开户资料■◆★◆、委托记录、交易记录等数据的保存期限不得少于20年;精神卫生法第47条规定,医疗机构对精神障碍患者病历资料的保存期限不得少于30年等。数据持有者在上述保存期限内不得以销毁、删除等方式对数据进行事实上的经营处分★★★■。
基于此,依据数据价值生成节点中法律关系的不同,数据权利可解构为数据生产关系、数据持有关系■★◆◆■◆、数据流通关系和数据征用关系四大权利模块。数据生产关系是数据持有者将与数据来源者有关的信息记录于数字化载体所形成的法律关系,涉及数据持有者与数据来源者的权利模块;数据持有关系是因数据持有者合法控制数据而相对于其他任何人的法律关系◆■◆★■,涉及数据持有者与其他任何人的权利模块;数据流通关系是数据持有者依据法律规定或合同约定向数据需求者分享提供数据所形成的法律关系,涉及数据持有者与数据需求者的权利模块;数据征用关系是数据征用者依照法律规定的权限和程序调取征用数据所形成的法律关系,涉及数据持有者与数据征用者的权利模块◆★◆★■。在上述四种法律关系中◆■★★■◆,数据持有关系由财产权的对世性衍生而来■■■,具有一般性■◆■★★◆、普遍性;而其他法律关系则在具体的数据价值生成互动场景中才会出现,具有特殊性、个别性◆◆■◆■★。
意定数据流通关系是基于合同约定建立的数据流通关系,采用个性化的权利模块分割方式。数据持有者与数据需求者可在数据流通合同中自主约定数据使用的目的■★★、方式、范围、期限、限制等■■◆■。
具体而言,数据征用的费用补偿应考虑两个方面:一是数据征用事件的紧急程度是影响补偿的因素★◆■。当数据征用者为应对突发紧急事件而必需征用数据时,例如应对突发公共卫生■◆◆、重大网络安全、自然灾害事件等◆★■,数据征用所维护的公共利益在位阶上明显高于数据持有者的数据经营自由,可免于数据征用者的补偿义务;而非紧急情况下的数据征用具有常态化■■◆★◆、持续性等特点■◆■◆,除法律特别规定的情形外,应赋予数据持有者向数据征用者请求支付补偿的权利。二是数据征用的补偿标准取决于数据持有者的企业规模。不同规模的数据持有者拥有的数字基础设施和掌握的数据传输技术存在差异★◆★★。相较于大型企业而言,在数据征用关系中承担数据提供义务可能会给中小企业造成更大的经济负担,故应适当提高对后者的补偿数额。如果数据持有者是大型企业,数据征用补偿应以数据提供所需的技术和组织成本为限,包括复制、传输★◆◆■◆、存储数据以及进行技术兼容性调整和采取安全保障措施的成本等◆★■★■;而如果数据征用的对象是中小企业,则在技术和组织成本之外,数据持有者还有权请求数据征用者支付额外的费用补偿★◆◆★◆,具体可参考数据的类型和数量,数据持有者的企业规模和商业模式,数据征用的目的、方式■◆★、用途、期限等因素予以确定。
为构建既适应数据价值生成规律又契合财产权设计原理的数据权利制度◆★,本文尝试将数据上各方主体的合法利益诉求标准化为不同层次的数据权利模块★★★★,并通过模块分解和整合实现数据权利的模块化设计。根据数据价值生成环节中法律关系的不同,数据权利可解构为数据生产关系、数据持有关系、数据流通关系和数据征用关系,分别涉及数据持有者与数据来源者、其他任何人、数据需求者★■◆◆、数据征用者之间的权利模块◆■★■★。各个数据权利模块既可经由模块封存将数据权属信息隐藏于内◆★,又能够通过标准化接口进行融合交互★★★,如此方能形成一套关于数据权利样态的复杂系统★◆◆◆◆★。数据权利的模块化设计不仅有助于精准地界分数据上各方主体的权利边界★◆◆★■◆,降低数据流通成本,而且能够与数据生产、数据携带、数据征税、数据安全管理■★◆、数据登记、数据交易、数据征用等诸多制度形成衔接,为构建数据流通交易◆★■、收益分配、安全治理等其他数据基础制度奠定基础,以此促进数字经济治理体系的法治化建设。
目前,学界对数据来源者权利争议较大的问题是:数据来源者能否以其为数据生产提供信息商业化利用机会或价值为由,向数据持有者主张分享数据载体层次上的财产利益?一种观点认为■■■■,数据生产源于数据来源者的网络接入行为■◆◆■■,其为数据的价值形成贡献了数字劳动,但由数字劳动创造的剩余价值和利润却被数据持有者垄断。为矫正市场失灵★■■★、促进数尽其用■◆◆■■,应当允许数据来源者直接参与数据财产利益的分配★◆。另一种观点主张■★★,单条或某个人的信息原材料所包含的财产价值很低■◆★,对此种“价值稀薄■★■★★”的财产利益进行确权势必要采取复杂的制度设计并付出高昂的运行成本,由此妨碍企业的正常数据处理活动■★◆■◆★,造成个人人格上的不平等。因此■★◆◆★,数据的财产利益应配置给数据持有者,并通过数据征税等再分配手段反哺数据来源者。
数据持有权是数据持有者自主管控数据并排除他人干涉的权利,旨在维护数据持有者对数据的稳定控制状态◆★■★★★。之所以“数据二十条”采用数据持有而非占有的概念◆■■★■★,主要是为了跳出所有权的思维定式◆★■■■◆,培育“淡化所有权、强调使用权”的新型产权观念。基于此,数据持有权具有下列不同于物之占有权能的特点■◆★◆◆★:一是持有主体的多元化。基于数据的非竞争性、非消耗性,数据持有无需遵从“一物一权”原则,而经常在同一宗内容的数据上呈现★■■“多重持有”现象,这也是数据不断流通复用的基础。二是持有方式的技术性。数据是从属于整个数字生态系统的单一要素,数据持有者无法对数据进行物理性的占有,而须依赖于对数据存储设备的控制、密钥控制、系统架构控制等技术手段予以管控,需要算法、算力、平台等的合力支撑。相应地,侵害数据持有权表现为盗窃或毁损数据存储设备、盗用密钥★★★、侵入计算机系统等形式◆◆。三是权利义务的复合性◆★■。数据持有是集权利★■■、义务于一体的复合性结构◆◆■★,数据持有者在数据持有关系中不仅享有面向不特定人的数据持有权,而且须负担个人信息保护◆★■■◆★、数据安全保护等义务,否则将丧失数据持有的合法性基础。
“数据资源—数据集合—数据产品”主要是从生产要素的角度对数据的经济学描述或形象化呈现,有利于清晰地观察数据在不同价值生成环节中的形态变化■◆★■★◆。但是,数据资源、数据集合、数据产品只能在同一数据价值链中进行形态划分,如果放眼于数个数据利用的价值体系,同一宗数据可能表现为截然不同的数据形态。例如◆■◆★,在网络运营者使用数据的价值链中,“生意参谋★◆”是对行为痕迹数据进行深度分析◆◆、整合形成的数据产品;但在人工智能服务提供者开展训练数据处理活动的价值链中,“生意参谋”却又是模型训练的数据资源。此外,数据资源、数据集合■★、数据产品与持有权、使用权、经营权之间并不存在严格的对应关系。一方面,就持有权和使用权而言,数据持有者不仅有权自主持有和加工使用数据资源或集合,而且对经过实质性加工的数据产品也享有持有控制和重复利用的权利;另一方面■◆■★★,数据经营权并非数据产品的“专利”,凡是具有使用价值和交换价值,能够分享、交换和重复利用的数据◆★◆★■★,都可成为数据经营和流通利用的对象。正因如此,“数据二十条”并未否定数据集合或原始数据的经营流通,而是要求“保护经加工、分析等形成数据或数据衍生产品的经营权◆★”,“审慎对待原始数据的流转交易行为”等。
一是反垄断授权★■◆。在数字经济时代,数据逐渐成为市场力量的来源,其能否依法有序流通将直接关涉数字市场竞争的公平性、透明性。通常情况下,数据持有者通过正当手段积累数据资源获得市场优势或谈判能力本身并不构成垄断,法律没有必要进行过多干涉◆■■■■;只有当数据持有者滥用市场支配地位排除或限制竞争时■★■◆◆,才应赋予数据需求者向数据持有者请求分享数据的权利模块,以实现法定数据流通。具体包括两种情形★■★■◆:其一■◆◆,竞争行为超出合理性边界★★■■◆。如果具有市场支配地位的数据持有者利用数据实施的竞争行为逾越公平竞争的边界,构成反垄断法第22条规定的滥用市场支配地位的行为,例如不合理定价、拒绝或限定交易◆◆◆◆■、商品搭售◆■■■◆■、差别待遇等,则数据需求者有权请求数据持有者分享数据◆■。例如,在某起数据抓取案中,甲公司通过robots协议歧视性地限制乙公司利用通用搜索引擎抓取其网页内容■★★◆★,有违公平竞争原则,因此乙公司有权请求甲公司解除对数据抓取的不合理限制★◆★■◆★。其二,必需设施规则。如果某种数据对于数据需求者而言构成必需设施,则具有市场支配地位的数据持有者负有向其开放使用该数据的义务■◆。在判断数据是否构成必需设施时,须从竞争秩序的角度出发★◆■■◆,结合个案数据在交易环节中所扮演的角色审慎认定◆■★■★★。只有当被数据持有者垄断的数据对于竞争企业进入市场或发展创新而言不可或缺,且其难以通过其他渠道合法获取时,数据需求者才有权根据必需设施规则请求数据持有者分享或提供数据。
有鉴于此,本文从数据权利的模块化设计原理出发,试图立基于数据生产★★、持有、流通★■、征用等价值生成环节界分数据持有者与不同相对方之间的法律关系,并在此基础上将各参与方的正当利益诉求标准化为数据权利模块,以期构建一套既符合财产权设计原理又适应数据价值生成规律的数据权利制度。
早在“数据法案”颁布前★◆■★,欧盟就已经在特别法中针对电力、机动车、支付账户等领域的法定数据流通问题作出了专门规定。例如,“欧盟机动车维修和保养信息获取条例”构建了汽车独立服务提供者对汽车维修和保养数据的获取和使用权,汽车制造者负有以非歧视性方式、合理且成比例的费用★◆★、标准化格式向汽车独立服务提供者提供开展业务所需的汽车维修和保养数据的义务。我国也率先在某些行业建立了纵向法定数据流通制度★◆◆◆。例如◆★★■,在公共数据领域,《北京市交通出行数据开放管理办法(试行)》确立了地面公交、轨道交通、静态交通、路网运行等交通出行数据向社会公众开放的法定流通制度;在私人数据领域,国家互联网信息办公室公布的《网络数据安全管理条例(征求意见稿)》第46条第4项要求平台运营者不得不合理地限制平台上的中小企业公平获取平台产生的行业■■■★◆、市场数据■★◆。可见,纵向法定数据流通能够有针对性地调整不同行业中数据获取的主体范围、数据类型、费用标准、传输格式、监管机构等◆■■,以此满足不同主体的数据利用需求。
最后■★★★■★,数据权利模块之间既彼此独立又相互依存。在对数据权利进行模块化分解后,各个权利模块“在单元(模块)内是相互依赖的,而在单元(模块)之间是相互独立的”。一是模块内部的信息隐藏■★◆◆◆★。据以组成数据权利的每个权利模块都是一个具有特定功能的子系统,其复杂性能够通过界面得以隐藏。各个数据权利模块仅须遵循各自的规则发生得失变更的效果,即每个数据权利模块的主体、客体、内容、取得、行使、保护等都可以在模块内部自主运行,而无需顾及其他权利模块的法律规则或变动状况。二是模块之间的权利边界。尽管数据权利模块在结构上彼此独立◆★■,但在模块之间却存在标准化接口。当同一宗数据上的两个或两个以上权利模块发生冲突时◆★★■■,法院可通过模块之间的标准化接口厘清权利位阶★★★■,以清晰地界分数据持有者与不同相对方的权利边界,实现数据权利整体的和谐稳定。三是权利模块的可延展性。正如一台电脑可通过外接设备或数字产品实现功能扩展,数据权利也可以通过扩充子模块或模块交互延展其内容。例如■◆★◆,通过扩充个人信息保护法第45条第3款规定的个人信息携带权,可形成涵盖所有数据来源者获取或复制转移由其促成产生数据的权利;通过观察数据持有者与数据需求者在数据流通环节的社会关系样态◆■,可赋予数据需求者依据法律规定或合同约定获取和使用数据的权利,由此形成弹性包容的数据权利制度■★。
总之■◆★★■◆,数据权利是由数据生产关系、数据持有关系■■★、数据流通关系和数据征用关系等模块分解、交互、整合形成的复杂系统★★■◆。下文将分别研究上述四大模块的权利配置问题。
模块交互是指将不同模块通过标准化接口相互联系的过程,主要涉及两个或两个以上的数据权利模块之间的接口设计◆★◆■◆,如此方能通过模块整合形成一套关于数据权利样态的复杂系统。具体而言★■,数据权利模块之间的交互关系可分为下列两种类型。
在数据生产中★★■◆★,数据来源者主动或参与贡献了信息原材料,其不仅有着对信息的法定在先权利在数据生产中不受减损的基本预期★■,而且具有分享数据商业化利用价值的利益期待★■■■★◆。因此■★◆★■◆,数据生产关系应首先在信息内容层次上为数据来源者分割出法定在先权利模块,其次考虑数据来源者能否向数据持有者主张财产利益的问题。
作为一种新型财产权◆★■■■◆,数据权利与物权■◆◆★、知识产权相比具有更高程度的复杂性和可分解性◆◆■,其从事实财产转化为法律权利的过程★◆,就是将数据上各方主体的正当利益诉求或主张标准化为权利模块的过程。
二是不同数据价值链中的外部交互关系。当同一宗数据同时处于不同的价值链时■◆,如果在先数据价值链中的数据权利模块与在后价值链中的数据权利模块存在利益冲突,则前者可能会构成对后者的限制★★★◆■。例如■★★◆,因数据持有者许可他人使用数据而开启新一轮数据流通利用的,前一个数据价值链中数据来源者的法定在先权利并不因此而消灭,数据需求者在新的数据价值链中仍须承担在先权利的保护义务■◆。又如,如果前一个数据价值链中数据持有者对数据需求者使用或经营数据的目的■■★、方式等作出了限制,那么数据需求者在新的价值链中持有◆■◆◆、流通数据也不得超出此授权范围。
法定数据流通的创设须调和数据的公共性和个体性两种价值:一方面,与有体物、智力成果相比,数据具有更强的公共性,且更容易被少数数据持有者汇聚或垄断,因此法定数据流通的标准和范围应相较于不动产的相邻关系◆■★、知识产权的法定许可和合理使用等更为宽松★■■◆★;另一方面,数据流通毕竟是受企业利益驱使的市场行为■★◆■★★,如果任由法定数据流通无限扩张,则会姑息纵容他人“搭便车”的行为◆■◆◆★■,不利于数据投资激励■★。
在横向法定数据流通之外,法律还可根据特定行业的组织模式★◆★◆■◆、市场结构、经济形态、商业惯例等确立纵向法定数据流通制度,从而为特定行业中的数据需求者赋予数据获取和使用权模块。纵向法定数据流通的设立不仅具有促进特定行业的市场竞争之目的◆■★■★,还要求具有经济学上的正当性,即创设数据获取权模块的社会总福利应大于数据持有者的私人利益和开放成本。
三是技术服务■★。即数据持有者以解决特定技术问题或改善特定行为效果为目的◆■◆■★■,向数据需求者提供以大数据应用为基础的技术服务◆★★★■,例如提供数据标注服务、定制个性化数据产品★★◆、提供可视化数据分析服务等。在数据技术服务中,数据持有者负有按照合同约定完成数据定制■◆★、数据标注等服务项目并向数据需求者交付工作成果的义务,以满足后者品牌策划、精准营销、项目风险评估等需要;而数据需求者则应当为数据持有者提供工作条件,并按照合同约定享有数据获取权★■★◆★、使用权、经营权等。至于数据持有者在向数据需求者提供数据技术服务后是否还有权保留数据副本以供其自行使用或许可其他需求者使用,则取决于数据流通合同的约定;合同没有约定或约定不明的◆■★,数据持有者负有删除数据备份或副本的义务。
二是强制许可。数据强制许可源于标准必要专利许可制度★■,是指依据法律规定的情形,数据需求者无须取得数据持有者的授权★■■◆★,就有权请求其公平、合理、无歧视地分享数据■★★◆,并支付数据使用费的制度。强制许可不以数据持有者具有市场支配地位或实施数据垄断行为为必要,其正当性源于民法典第494条第2-3款规定的强制缔约义务。尽管数据强制许可有助于弥合大型平台与中小企业的“数据鸿沟◆■”,但其毕竟干涉了数据持有者的缔约自由★◆,法律应对其设置严格的适用条件:其一,数据难以自行生产或通过其他来源获取。只有当受限于知识产权、技术兼容性、用户基础等因素◆■■◆★,数据需求者生产或获取数据所需的时间和技术成本明显与数据获取的经济利益不成比例时■◆★◆◆,才会阻碍数据需求者参与数据市场竞争★◆★,进而具有创设数据强制许可使用权模块之必要。其二■◆★,数据流通不会导致数据持有者丧失竞争优势。为避免对数据投资激励造成负面影响,数据强制许可不宜强制要求数据持有者向其竞争对手提供竞争性资源,而应限于数据流通不会导致数据持有者丧失竞争优势的情形。其三◆★■,数据需求者应支付数据获取或使用费★★◆★★◆,包括分享数据的成本和为维护数据持有者的商业利益而附加的利润等。
构建数据持有关系的权利模块★◆■◆■,首先要确定数据持有者的权利客体指向。“数据二十条★◆■◆★■”第3条确立了数据资源持有权■★、数据加工使用权和数据产品经营权等分置的运行机制。有观点认为★■■◆★◆,“数据三权”的客体分别指向数据资源(或原始数据)、数据集合和数据产品★■。也有观点将数据权利客体分为数据资源和数据产品两种形态。《深圳市数据产权登记管理暂行办法》第2条明确将“数据资源和数据产品的权属情况及其他事项”作为数据产权的登记对象■★■◆。
综合来看,上述两种观点均不否认数据来源者对数据生产作出了贡献,其争论焦点在于:应当如何根据数据来源者的贡献使其分享数据的财产利益,究竟是直接为数据来源者创设■■■“个人数据财产权”或“个人数据收益权”◆★★★,还是采用数据征税这种集体转移支付的方法★■★■。从模块化设计的视角看★■◆◆,数据来源者权利隶属于数据生产关系,承认数据来源者对数据财产利益的分享,并非要为其配置具有支配性、绝对化的数据财产权模块,而是要使其在与数据持有者的交往互动中享受便捷■◆、高质量的数字产品或技术服务,这既符合数据来源者为数据生产贡献信息原材料的初衷,也是“以数据换服务”模式的核心要义。有疑问的是■■,当数据来源者贡献的信息原材料与数据持有者提供的数字产品或技术服务的价值明显不对等时,法律应如何进行数据要素收益的公平分配?对此,“数据二十条”明确指出◆◆■,“通过分红★■◆★、提成等多种收益共享方式,平衡兼顾数据内容采集、加工、流通、应用等不同环节相关主体之间的利益分配★★■★★”★★◆◆■■,这当然包括兼顾数据来源者与数据持有者的数据财产利益分配。至于数据财产利益的分配方式,首先应当取决于当事人的合同约定。如果数据持有者在合同中约定向数据来源者分配数据财产利益或给予与其贡献的信息原材料相应的金钱对价■◆■◆★,则应当尊重双方作出的合同安排★◆■■。例如,在实践中◆★,某汽车企业于2021年在智能汽车领域首创■■“CSOP用户数据权益计划”,该计划将创始股东拥有的4★◆◆★◆■.9%的股权收益回馈给贡献数据的用户,并以用户车辆行驶里程数据作为原石“开采”的主要输入■★■,新用户可使用原石和现金兑换激光雷达融合智驾硬件系统,由此激励用户向该汽车企业贡献行驶里程数据,赚取股份收益和硬件系统■◆■◆。
数据持有者在持有控制数据后★★■◆◆◆,可依据法律规定(法定流通)或合同约定(意定流通)将数据投入流通环节,从而在数据持有者与数据需求者之间成立数据流通关系★■■◆■◆。
在数据价值链中,数据的价值形成起源于数据来源者提供信息原材料★★◆★■■、数据持有者记录生成数字化载体的数据生产活动,其核心问题是如何在数据生产关系中实现数据来源者与数据持有者的权利均衡配置◆■。
一是转移控制★■■。即数据持有者将数据控制权限一次性整体让渡于数据需求者★■,例如交付数据存储硬盘★◆、转移数据库或数据包等■★,其类似于专利权◆■■★■、技术秘密的转让或有体物的所有权让与。数据持有者在转移数据控制后将完全丧失数据权利,无权再行使用或经营数据;而数据需求者代替数据持有者的地位获得完整的数据权利,享有依其自主意志持有管控、开发使用和经营数据的权利,并有权请求原数据持有者删除数据原件或副本★■。
可见,模块化作为数据权利的基础性架构,不仅直观地呈现了多主体围绕数据分享利益的格局,而且维持了数据权利的开放性和生命力。因此,有必要根据模块化理论对数据权利进行模块分解与整合。
关于数据征用★★★,◆★“数据二十条★■★★◆◆”第5条规定,“政府部门履职可依法依规获取相关企业和机构数据■★■★,但须约定并严格遵守使用限制要求”★◆◆◆■。之所以本文采用数据征用而非数据征收或使用的表述,一方面是因为国家机关获取私人持有的数据通常采用普通许可的流通方式★★◆,其并不转移数据控制权或剥夺数据持有者的数据使用权;另一方面,国家机关的数据获取具有依托公权力保障实施、公益性、强制性■◆、法定性等特点★◆◆★■,其本质上是一种公法上的行政行为,因此又不同于私人数据需求者的数据使用◆◆■。当然■■◆◆◆■,数据征用与民法典第117条、第245条规定的不动产或动产的征用也存在区别,其仅构成对数据持有者的数据经营权而非整个数据权利的限制◆■◆。在满足法律规定的权限和程序时,法律授权的国家机关无须取得数据持有者的授权,就享有依法获取和征用数据的公权力,而数据持有者有义务向数据征用者提供数据。
有鉴于此,法定数据流通的创设须遵循下列准则:一是比例原则★★■◆。法定数据流通应遵守比例原则,即流通应限于实现数据流通目的的最小范围,采取对数据持有者影响最小的流通方式,以确保数据流通自由或其承载的公共利益与对数据持有者权利的限制程度及由此造成的数据安全风险之间保持适当比例。例如,倘若数据需求者小规模获取数据以满足生产经营需要◆◆■,则可纳入数据合理使用范畴;但其为追求经济利益大规模抓取数据的,该行为显然已超出数据流通目的、方式的限制。二是数据使用权限的限制。数据需求者获取数据的目的在于实现其分析价值,法律只需赋予数据普通许可使用权即可满足其数据利用需求,而既不需要通过转移数据控制剥夺数据持有者的数据权利,也没有必要采用独占许可、排他许可等具有排他效力的流通方式■■。三是横向流通和纵向流通相结合原则。根据法律授权范围的差异,法定数据流通事由可分为横向跨行业的法定流通和纵向特定行业的法定流通■■★。为节约立法成本并兼顾不同场景下的数据获取需求,法定数据流通的创设应坚持横向流通和纵向流通相结合原则◆■★◆,即在统一建立适用于所有领域的法定数据流通规则的基础上,允许特定部门或行业(例如汽车维修、农业生产、智能家居★◆◆■、医疗卫生等)根据实际情况调整或细化具体流通方案,形成一套纵横交错的法定数据流通制度。
数据征用须满足以下条件:一是为了维护公共利益■★◆◆◆。公共利益是数据征用的目的限制要素,其要求数据征用的类型和数量应以维护公共利益所必需的范围为限。相较于不动产或动产的征用而言■★◆,由于数据征用通常不会对数据持有者的竞争利益造成影响,其公共利益的界定可适度宽松化★■◆◆■★,不限于民法典第245条规定的“抢险救灾、疫情防控等紧急需要”,还包括维护国家安全、公共卫生利益★■、侦查和起诉犯罪、统计调查、空间和城市规划、环境保护和能源供应等情形。二是符合法律规定的权限和程序。作为一种行政行为◆★,数据征用须符合法律规定的权限和程序,不得超越或滥用职权侵害数据持有者的数据权利或其他合法权益★★★■◆。例如★★,根据国家情报法第16条◆◆,国家情报工作机构工作人员在满足◆■■“依法执行任务”“经过批准”★■◆■◆◆“出示相应证件”等条件时◆◆■★,有权依法查阅或调取有关档案◆★◆、资料★◆◆。又如,网络安全法第30条规定◆◆■★,网信部门和有关部门在履行网络安全保护职责中有权获取数据,但该数据只能用于维护网络安全的需要■★◆。三是除法律另有规定外,数据征用者应以书面方式、清晰易懂的语言向数据持有者告知数据征用的目的、方式◆★★、用途、期限■◆◆◆★■、法律依据等,并依法采取技术和组织措施维护数据的机密性、完整性和数据传输的安全性■★,不得泄露在此过程中知悉的个人信息、隐私、商业秘密、智力成果等。
“所有产品都是模块的组合◆◆◆。”模块意为半自律的子系统,是指在系统中承担独立功能的标准化单元或组成部分,或者用以组成更大系统的独立集合体★★★◆■。作为一种通过标准、界面■◆◆◆★★、规则等管理复杂系统的设计方法■■■★,模块化理论发轫于工业汽轮机■◆、汽车、船舶■★、电子设备◆★■、计算机等产品制造领域,其原理是将复杂产品分解为一系列独立功能的模块,并通过模块的整合和重组配置形成满足不同用户需求的标准化设计◆■★■◆,以此化繁为简◆◆■■★,降低产品设计和制造成本★■◆■◆■。20世纪90年代以来,模块化理论开始由产品★◆◆■、流程设计转向组织分析和管理,逐渐成为社会学、经济学、管理学★■★◆◆、心理学等通用的方法论◆◆★★★■。美国法经济学家亨利·史密斯首次将模块化原理引入财产法◆◆■,开创了财产权模块化(Property as Modularity)的新范式。史密斯教授在批判英美法长期将财产权视为去结构化的权利束的基础上,认为财产权类似于组织商业公司的模块化系统或互联网信息系统■■◆◆,其本质是由一系列可分解的模块或子系统构成的复杂立体结构。其中每个模块既封装或隐藏了相互区隔的内部信息,避免因单个模块的演化而对权利整体造成不可预测的连锁反应;又存在与其他模块融合交互的标准化接口◆★■,拓展了权利的深度和广度。财产权的内容和效力并不决定于半自律的子系统本身,而是取决于各个权利模块组合而成的整体结构。
其次,数据权利可分解为不同标准化程度的权利模块。如同一辆汽车可分解为制动系统、燃油系统、传动系统、刹车系统、转向系统、引擎控制系统等诸多模块化组件,一宗数据上的各种权利样态也可以进行分解。这种权利分解并非杂乱无章或毫无规律的,而须着眼于数据价值链中的典型社会关系予以系统性观察,使分解后的权利以不同标准化的模块形式呈现■◆◆■。在现行法上,法律已经将数据上凝聚社会共识★◆、边界清晰稳定的部分权利条块进行了模块化分解。例如,个人信息保护法通过规范个人信息处理活动,将承载于个人信息数据之上的数据来源者与数据持有者的法律关系进行了模块化处理■◆◆★■,个人信息数据来源者享有以知情权、决定权为核心的个人信息权益;反不正当竞争法第9条第1款通过列举侵犯商业秘密的四种行为◆★★■◆,确立了权利人对技术信息、经营信息等商业信息享有的商业秘密权利模块等◆◆◆。但是,对于数据持有者是否享有数据财产权、数据需求者如何获取和使用数据、数据来源者能否向数据持有者主张分享数据财产利益等问题,则有待于法律对数据权利进一步作出模块化分解★◆★■★。
SCM系统能够对企业的库存进行监控和计划,以确保库存水平的合理化■■,避免库存过剩或缺货的情况发生。
SCM系统(Supply Chain Management)是指一种通过使用信息技术和先进的管理方法■■■,以优化供应链流程,提高生产和运作效率的系统。SCM系统的目标是协调和整合各个环节的供应链,以满足消费者需求,同时最大程度地降低成本。
选择适合的SCM系统供应商需要考虑多个因素◆★◆★■,包括供应商的经验和专业能力◆◆■★◆■、系统的稳定性和灵活性◆★■◆、服务和支持的质量等。企业可以通过与供应商的对话和参考其他用户的经验来进行评估和选择。
SCM系统能够帮助企业制定和执行供应链规划,包括预测需求、制定采购计划和生产计划等★◆◆■◆★,以确保供应链的顺畅运作。
评估SCM系统的性能和效果可以从多个方面进行■★★★◆,包括供应链的准确性、交货时间的准时性、库存水平的合理性等。同时,企业也可以通过与供应商和客户的沟通和反馈来评估SCM系统的效果。
SCM系统作为一种优化供应链管理的利器◆◆■◆★,对企业来说具有重要的价值和意义。通过合理的规划◆★★★■■、协调和管理,SCM系统可以帮助企业提高供应链的效率和灵活性■◆■★■,降低成本和风险■★◆★。在日益激烈的市场竞争中,实施SCM系统对企业来说已经成为迫切的需求■■★■。
SCM系统通过提供实时的供应链信息,使不同环节的合作伙伴能够共享信息★★■■,加强沟通和协作。
SCM系统可以帮助企业优化运输和配送流程◆◆★■,提高货物的运输效率和准时交付的能力。
SCM系统可以帮助企业管理供应商的选择和评估■★★■★★,与供应商建立紧密合作关系■■★,并监控供应商的绩效★◆。
SCM系统可以适用于几乎所有的行业★◆★,包括制造业、零售业、物流业■★★◆、医疗业等。不同行业的企业可以根据自身的需求和特点来选择最适合的SCM系统。
SCM系统可以通过对供应链中的信息进行实时跟踪和分析■★◆◆,以应对供应链中的不确定性。同时,企业也可以通过建立灵活的合作关系和供应链风险管理机制来降低不确定性带来的影响。
SCM系统通常需要配备一些先进的信息技术工具★■◆,例如ERP(企业资源规划)系统、CRM(客户关系管理)系统等◆■★,以支持供应链信息的管理与共享。

SCM系统对企业来说具有重要意义。它不仅可以提高供应链的效率和灵活性★■★★,还可以降低成本和风险。通过实施SCM系统◆★★■,企业可以更好地满足客户需求,提升客户满意度;同时★■◆◆■■,也能够帮助企业在激烈的市场竞争中脱颖而出,实现可持续发展★■。
1, the product independent design, surface spray, beautiful appearance, small working radius, can work in a narrow area. 2, the use of Japan KYB plunger variable pump, so that the big arm, the forearm, the rotation form their own independent hydraulic system, to achieve fast and smooth and strong operation. Compared with gear pump, it has obvious performance advantages. 3, the main valve adopts the parker main valve, with efficient performance and excellent operating performance, with crushing pipe and control device, the installation of crushing hammer can be broken work. 4, Rotary Eaton 2.5K rotary motor, reliable quality, large displacement, large torque, strong adaptability to working conditions. 5, Eaton imported walking device, more stable performance, more reliable quality. 6, the left and right pilot handle choose short handle control valve, without affecting the performance of the premise, it is more convenient to get on and off the car, prevent misoperation, and increase safety. 7, imported Yanma three-cylinder water-cooled diesel engine, more powerful, imported hydraulic system, high configuration, superior performance, low fuel consumption. 8, a wide range of operations, the use of quick replacement of joints, optional rotary digging drill, crushing hammer, loading bucket, grab and other accessories. 9, reduce maintenance and operating costs, liberate labor, improve mechanization, low investment, high return.
When buying a mini excavator, you can choose according to the model according to the following steps:
Understand the needs: First determine your specific needs for micro excavators, such as digging depth, digging scope, working environment, etc. Knowing the requirements can help you choose the right model.
Research the market: Research the brands and models of mini excavators available in the market. Understand the differences between different brands and models, including technical parameters, quality, price, after-sales service, etc.
Small excavators are suitable for a variety of working environments, rather than manual working environments. Main users, ditches, landscaping, cable lines, trees planted on top of mountains, greenhouses for vegetables, improved agricultural land, basements, concrete, are other small Spaces. The machine adopts domestic engine, mechanical operation, ergonomic optimization, and unique joystick optimization to make the driver's operation more convenient and comfortable.
Small excavators can be used to dig greenhouses and ditches. This is a small excavator that can be used indoors. Saving labor and space is a rare advantage. It is widely used in the water business. Low cost purchase and high survival rate is everyone's evaluation. Not surprisingly, microshovels are also being used to build power projects. Filling the rod was previously a difficult task, as one had to use manual drilling and it was inefficient. Now everyone is using small excavators, nearly ten times faster than before. The other is called a multi-purpose mini excavator: not only does it have a bucket, it can also damage the ground and be equipped with a crushing hammer to tear down the house. Adding an auger can be a great aid in gardening tree holes and planting. Compared with ordinary excavators, micro drilling machines are small in size, easy to operate, and choose the built environment that many people like. Today, Xiaobian introduces how micro-drilling machines can help orchard construction in order to better understand micro-drilling machines.
Micro excavators dig ditches
It is mainly applicable to the loose land of agricultural vegetable greenhouses, the construction operations with narrow space such as the greening of municipal departments, planting trees and digging of orchard nurseries, breaking of concrete pavement, and mixing of sand and stone materials. It is the ideal equipment for continuously replacing labor and liberating labor force in the future.
Small excavators can be used to dig greenhouses and ditches. This is a small excavator that can be used indoors. Saving labor and space is a rare advantage. It is widely used in the water business. Low cost purchase and high survival rate is everyone's evaluation. Not surprisingly, microshovels are also being used to build power projects. Filling the rod was previously a difficult task, as one had to use manual drilling and it was inefficient. Now everyone is using small excavators, nearly ten times faster than before. The other is called a multi-purpose mini excavator: not only does it have a bucket, it can also damage the ground and be equipped with a crushing hammer to tear down the house. Adding an auger can be a great aid in gardening tree holes and planting. Compared with ordinary excavators, micro drilling machines are small in size, easy to operate, and choose the built environment that many people like. Today, Xiaobian introduces how micro-drilling machines can help orchard construction in order to better understand micro-drilling machines.
Small excavator is also known as small mining machinery, the definition of small excavator is also different, such as: in the country where the excavator loader is sold (such as the United Kingdom, France and Italy), 1 to 3 tons of small excavator products are the mainstream. In countries where the use of excavator loaders is not very common (such as Germany), it is more inclined to use 4-6 tons of products. However, almost all countries tend to buy larger equipment, so we conclude that the definition of small excavators is 1 to 6 tons of excavators can be called small excavators, of which 2.7 to 3.0 tons of products accounted for a larger proportion, the reason is that they can easily use common transport vehicles for ground transfer. Small excavators benefit from their small size and become ideal equipment for earthmoving applications mainly in urban areas.
A small excavator developed and manufactured for domestic modern and scientific production, suitable for all kinds of working environments instead of human labor, the main user orchard digging trenches, landscaping, cable pipelines, mountain planting trees, greenhouse vegetables, farmland transformation, basement, concrete crushing and other small Spaces. The equipment adopts domestic engine, mechanical control, ergonomic optimization and patented control handle, so that the driver's operation is more convenient and comfortable.
We’re just a few weeks away from SEMA 2017, and Mike and Jim Ring of Ringbrothers are burning the candle at both ends and in the middle to get three cars done for the show. They took time out of their busy schedule to talk to us on the podcast, though.
These sibling started out as two regular guys running their dad’s repair shop, and amazing as it may sound, they still churn out production collision work to keep the lights burning. But for a good chunk of the year, they’re banging out some of the coolest cars you’ve ever laid eyes on.
Witness 2014’s “Recoil,” the killer ’66 Chevelle that lit up social media after it was introduced in the Royal Purple booth that year.
Under the hood, the ’66 Chevelle features a Wegner Motorsports LS7 V-8, breathed on by a Whipple supercharger for 980 horsepower. One-off fuel rail covers exactly match the design of the blower’s case. The fuel injection system comes from Holley, with an Aeromotive fuel cell and pump.
The brothers are hard at work on three vehicles for the show this year, and as we talked, they emailed their renderings.
The first is an AMC Javelin AMX. We’ve seen some pretty wild two-seat AMX customs before, but it’s about time the four-seat Javelin AMX got its due. We’re dying to see what this one looks like when it’s finished.
The second is SEMA fodder: a 1969 Dodge Charger. But once Ringbrothers have their way with it, it’ll be stretched, widened, lowered and stuffed with the latest 1,000-hp mill from the SEMA floor.